Hvad er performance når det handler om softwareapplikationer, der skal yde så godt som muligt og svare tilbage så hurtigt som muligt. Ofte er begrebet performance ikke defineret ordentligt, og specielt ikke hvad kravene til performance er for et givent softwaresystem. På universitetet havde vi ikke kurser der handlede om performance. Hverken hvordan man måler performance eller hvordan vi kan opnå en bedre performance når vi udvikler software. Vi lærte heller ikke at bruge en debugger, en profiler eller et analysetool til at analysere koden, så man kan blive klogere på hvad der rent faktisk sker på run-time.
Performance kan deles op i to ting: Throughput og Latency. Throughput kan betragtes som ”båndbredden” fx antal transaktioner pr sekund, operationer pr sekund osv. Latency er den tid, som en applikation eller et system bruger på at processere et request eller noget data. Latency kan deles op i flere kategorier, fx latency gennem hele systemet, latency i sub-komponenter, low-level netværks-latency etc. Så latency handler om hvor hurtigt applikationen kan få data fra den ene ende til den anden ende, eller hvor hurtigt man kan få et svar efter at have sendt et request.
Latency og throughput er forbundet til hinanden, hvilket kan ses ud fra nedenstående graf (som er taget fra dette foredrag, og hvis man vil lære mere om performance testing af java applikationer, så se dette foredrag):
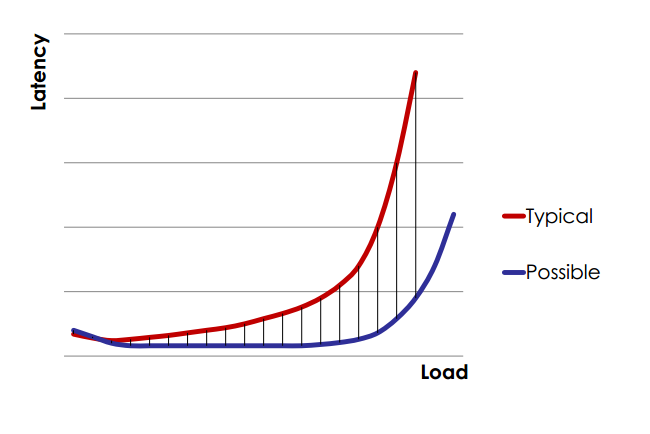
Den røde graf viser hvordan softwareapplikationer opfører sig under normale omstændigheder: når load’en på systemet kommer over ca 80% så stiger latency på systemet kraftigt, dvs. svartiderne bliver så høje at systemet holder op med at fungere optimalt for brugerne.
Det er dog muligt at få en lavere latency trods et højt load (jvf. den blå graf), men det kræver et software design og implementation der bygger på principperne bag The Reactive Manifesto (som i øvrigt er kommet i en version 2.0).
Tilbage til kravene: det sker desværre alt for ofte, at der i et softwareprojekt sjældent bliver sat nogle specifikke krav til systemets latency og throughput. Disse krav skal fastsættes tidligt i projektet. Hvilke værdier er realitiske og hvilke værdier skal systemet kunne klare for at være responsive. En applikation (stor som lille) skal være responsive, ellers er den ikke brugbar, hvis man skal vente for længe for at få et svar eller for at få processeret noget data.
En anden vigtig ting er at man bør begynde at udføre performance tests tidligt i et projektforløb. Faktisk bør man følge tankegangen bag TDD, og skrive performance tests som det første. Det er også en rigtig god ide at sætte et performance continuous integration system op at køre når projektet starter. På denne måde kan man hurtigt se hvis et commit får indflydelse på performance, dvs. hvis systemet har en dårlig performance, så bør det få dit continuous integration byg til at fejle. Hurtige feedback cycles er lige så vigtige når det gælder performance, som når det gælder fejlfinding i kode eller kundeinddragelse.
Alt for ofte bliver performance tests først udført på softwaresystemer i en afsluttende release-fase, eller endnu værre: man opdager først (måske helt tilfældigt) en dårlig performance, når systemet allerede er deployed ude hos kunderne og sat i produktion. Derfor er det vigtigt at opdage eventuelle performance bottlenecks så tidligt som overhovedet muligt i udviklingsprocessen, da det så er nemmere og billigere at få løst performance problemerne.
Hvordan analyserer og håndterer vi så performance problemer når vi opdager dem? Mange gange ender det med at vi søger i blinde for at finde et svar, der kan løse problemet. I stedet skal vi gå systematisk til værks og analysere softwaren med forskellige analyseværktøjer samt instrumentere koden, så vi bedre kan analysere de forskellige trin eller flows, og dermed opdage hvor performance problemerne stammer fra. Og vi skal bruge en debugger og en profiler langt oftere, for netop at blive klogere på vores egen kode.
Som det sidste vil jeg nævne at performance testing er alle team-medlemmers ansvar, og man bør ikke have et dedikeret “performance team” i en organisation, men derimod se på performance testing som en roterende øvelse blandt alle i team’et. Hvis der findes performance specialister in-house skal de dele deres viden, så vi alle kan blive bedre til at teste, måle, analysere og forbedre performance.
I del 2 af dette blogindlæg vil jeg komme ind på bl.a. performance histogrammer, definere forskellige typer af performance tests og inddrage performance teori.
Det er altid en fornøjelse at læse dine indlæg. De er velskrevne og velovervejede. Tak for det 🙂
[…] kan også gøre som jeg beskrev i forrige indlæg om performance testing, og sætte et continuous performance testing system op, som eksempelvis […]