Del 2 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem
Del 3 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem
Del 4 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem
Nu er vi endelig nået frem til den spændende udvikling jeg hintede til i SOA – Hierarki eller organisk vækst?
I sidste blog post SOA: synkron kommunikation, data ejerskab og kobling gennemgik vi de 4 Principper for Service Orientation og fokuserede specifikt på Service ansvars afgrænsning og autonomi problemerne med (synkron) 2 vejs kommunikation mellem Services. Med den viden er vi godt rustet til emnet for denne blogpost.
Emnet, som titlen indikerer, er micro services, der på mange måder er et modsvar til monolitiske arkitekturer. Lige som for SOA har Micro services desværre heller ikke nogen klar definition. Det eneste man kan blive enige om er, at de er små og de er individuelt deployerbare. Tommelfinger reglen er 10-100 linier kode (for sprog med minimal ceremoni og excl. frameworks og libraries – selv om det sidste er til diskussion blandt puristerne). Antal linier kode er efter min mening en horribel måle stok til at afgøre om en (micro) service har den rette størrelse eller for den sags skyld er en god service.
Der mangler generelt nogle gode retnings linier for at designe micro services mht. ansvarsområde (størrelsen) og integrations form (hvordan man bruger dem). Uden disse retnings linier bliver det svært at adskille skidt fra kanel og man kan nemt fristes til at påstå at den udskældte lagdelte SOA (se tegningen nedenfor) også overholder micro service tommelfinger reglen (og så ved vi godt at nogle vil fristes til at krydse micro services af på deres liste og sige at dem har de også, uden at kigge nærmere på hvad micro services handler om og dermed aldrig komme i nærheden at designe ordentlige micro services).
Så er services i en klassisk lagdelt SOA reelt microservices?
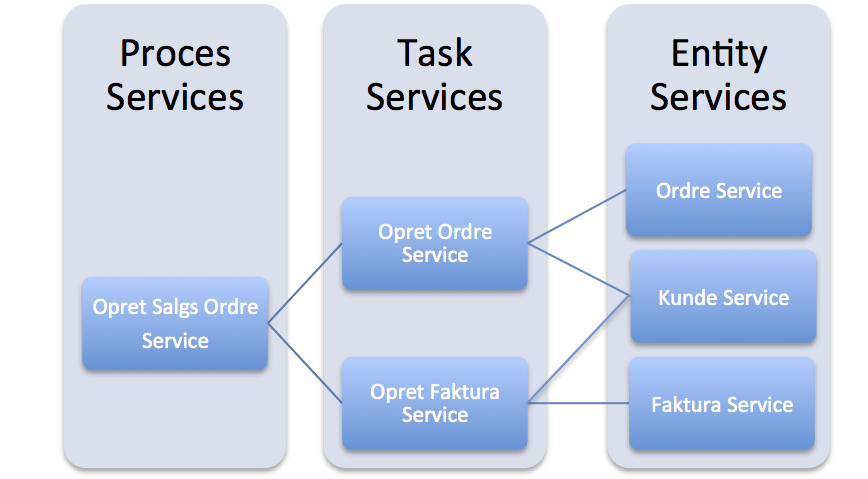
Er lagdelt SOA også en microservice arkitektur?
Entity/Data Services er tynde services der har omtrent samme rolle som en Repository/Data-Access-Object fra klassisk lagdelt OO kode. En Entity service er en tynd skal oven på en (typisk) relationel database. Alt efter sprog og framework kan et (REST/Web) Service eksponeret Repository implementeres på 10 til ca. 300 liniers kode.
Micro service størrelses regel overholdt – CHECK
Task services er tynde services der koordinerer/orkestrerer kald til flere Entity services. Alt efter framework/library og omfang af data konvertering kan det implementeres med 10 til 1000 linier kode.
Micro service størrelses regel overholdt – CHECK til omtrent check
Proces Services er tynde til semi tynde services der koordinerer kald mellem flere Task services. Der er typisk lidt mere arbejde i koordineringen, da der typisk er behov for både at konvertere data, håndtere kompensationer i tilfælde af opdaterings fejl samt behov for lange transaktioner. Alt efter framework og library (f.eks. BPEL og en ESB) kan en process service implementeres på 100 til nogle tusinde liniers kode.
Micro service størrelses regel overholdt – omtrent CHECK
Som vi diskuterede i SOA: synkron kommunikation, data ejerskab og kobling er (synkron) 2 vejs kommunikation, som anvendes i lagdelt SOA, dybt problematisk mht. Service ansvars-afgrænsing og service autonomi. Blot behovet for kompensationer i process og tildels task services involverer en del kompleksitet. Et andet problem er kontraktuel og temporal stabilitet. Hvis blot én enkelt service er nede, er der intet eller meget lidt der fungerer. Latens tiden (tiden fra en service bliver kaldt til der er svar) er typisk også høj, da der skal kommunikeres med mange services over en netværks protokol.
Udelukkende ud fra reglen om at Micro services indeholder få linier kode kan man med tilnærmelse sige at Entity/Task/Process Services alle er microservices. Det viser, med al tydelighed, at anvendelsen af linier kode til at afgøre om en service er en micro service eller for den sags skyld en god service er elendig!
Latens tiden bliver ikke mindre hvis vi dekomponerer vores services yderlige og laver rigtige micro services og bagefter lader dem kommunikere 2 vejs. Hvis omdrejnings punktet for micro services udelukkende er størrelse og ikke anvendelses formen er det ikke svært at forestille sig et stjerne diagram af services: Vores applikation kalder en service der igen kalder en masse små (genbrugelige) services, der potentielt kalder en andre services, der igen kalder andre services. Cirkulære kald bliver også svære at undgå.

Micro services stjerne 2 vejs (synkron) kommunikations diagram. Service kalder services der kalder services, etc.
I vores forsøg på at dekomponere vores services har vi fået lavet dem meget små (f.eks. ansvarlig for få data attributter). Det skaber nemt den udfordring at de individualle services for behov for at snakke med hinanden for at kunne udføre en opgave. De bliver så at sige misundelige på hinandens data og funktionalitet.
Et af målene med service orientering var at sikre genbrug. Hvordan sikrer man højest mulig genbrug? Lav alle service så små at de kan genbruges i så mange forskellige sammenhænge som muligt.
Logikken er fin, problemet er blot at hver gang vi har genbrug har vi også kobling. Et af de andre mål med service orientering var at sikre en løs kobling så vi nemt kan kan ændre i vores services for at følge med forretningen.
I SOA: synkron kommunikation, data ejerskab og kobling diskutterede vi at (synkron) 2 vejs kommunikation medfører nogle ret hårde former for kobling der ikke er ønskværdige:
- Kommunikations mæssig kobling (data og logik ligger ikke altid i samme service)
- Lagdelt kobling (sikkerhed, persistens ligger ikke i samme service)
- Temporal kobling (vores service kan ikke fungere hvis den ikke kan kommunikere med de services den afhænger af)
Kobling har den side effekt at den skaber kaskade effekter: Når en service ændrer sin kontrakt bliver det noget ALLE services der er afhængige af servicen skal forholde sig til. Når en service er utilgængelig er alle services der afhænger af servicen reelt også utilgængelige. Når en service fejler i forbindelse med en data opdatering bliver alle andre services der er involveret i samme koordinerede process/opdatering også nød til at forholde sig til den fejlede opdatering (process kobling):
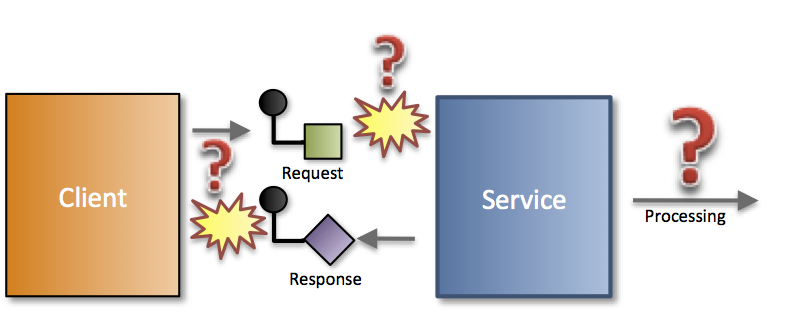
Skete fejlen inden servicen modtog beskeden og udførte opdateringen eller skete det efter?
I eksemplet ovenfor udfører en klient, som kunne være en anden service, et kald mod en service. Da kommunikationen er 2 vejs foregår kaldet ved at klienten sender et Request besked til Servicen. Servicen modtager Requestet og udfører en eller anden form for processering, f.eks. opdatering af en database. Efter endt processering sender Servicen en Response besked tilbage til klienten for at indikere resultatet. Kommunikationen foregår via netværket, f.eks. HTTP kald eller Kø beskeder. Netværk er langsomme og mindre pålidelige end de in-memory kald som vi er vant til fra vores monolitiske applikationer.
Hvis klienten løber ind i en timeout eller anden form for netværks IO fejl er der typisk 2 årsager:
- Enten nåede Request beskeden ikke frem til Servicen, som derfor ikke opdaterede databasen.
- Eller også nåede Request beskeden frem og Servicen opdaterede databasen, men Response beskeden nåede aldrig tilbage til klienten.
Manglen på Reliable Messaging gør at klienten ikke ved om Servicen har udført opgaven og den står nu med et problem: Hvad skal den gøre?
- Skal den forsøge at spørge Servicen om kaldet gik godt og i tilfælde af at det fejlede genprøve kaldet?
- Skal den blindt prøve kaldet igen?
- Skal den prøve at kompensere for kaldet?
- Eller skal den give op?
Sidste reaktionen plejer at være den fremherskende løsning.
Hvis klienten prøver kaldet igen skal Service operationen være implementeret så den kan håndtere flere ens kald/request beskeder og stadig kun udføre sin opdatering een gang (også kaldet idempotens).
Hvis kaldet til Servicen var en del af en serie opdaterings kald til flere Services står vi med et større konsistens problem, da vi ikke har, kan eller bør benytte distribuerede transaktioner til at håndtere koordineringen af opdateringen. Som vi så i SOA: synkron kommunikation, data ejerskab og kobling er kompensations logikken ikke nødvendigvis triviel eller simpel at implementere med 2 vejs kommunikation:
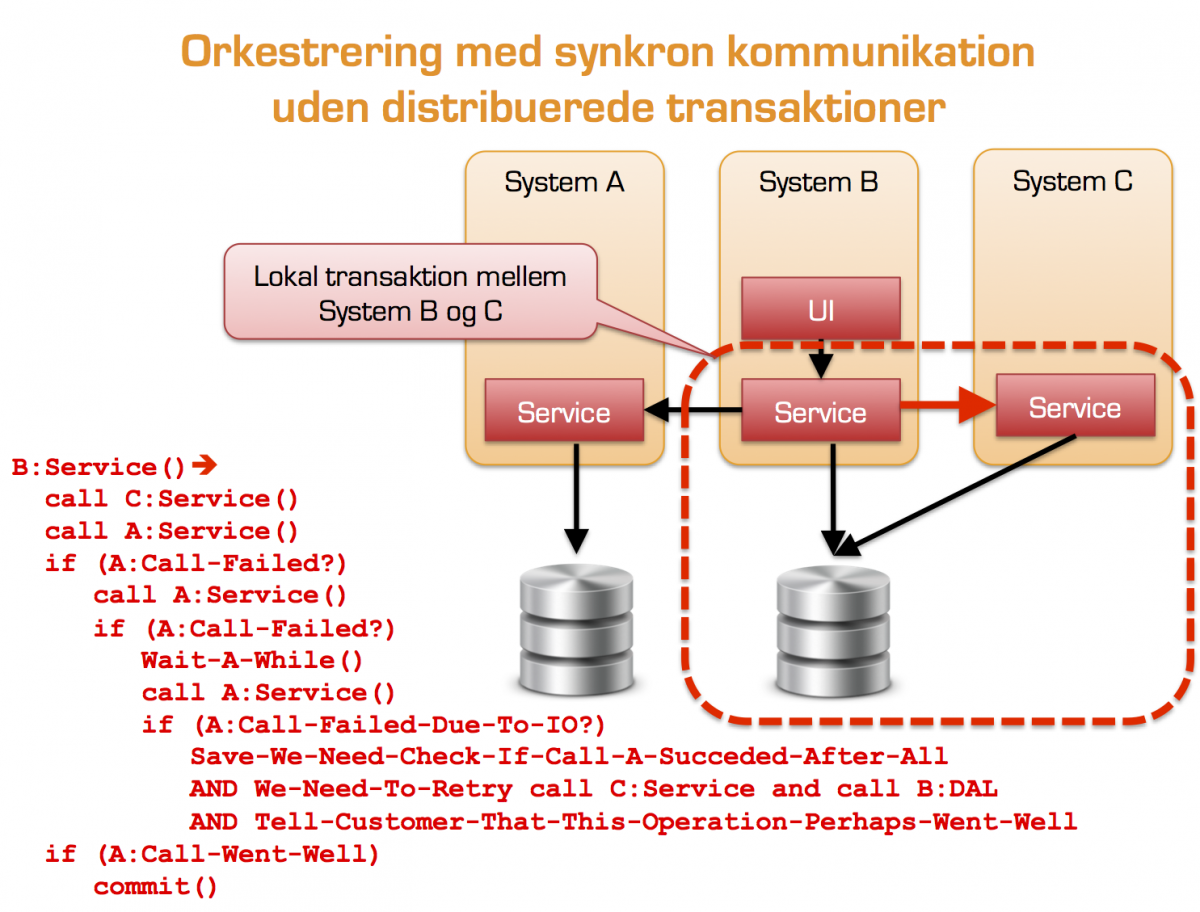
Transaktions kompensation ved (synkron) 2 vejs integration
Forestil dig en ekstrem micro service arkitektur hvor hver service kun er ansvarlig for een attribute (f.eks. fornavn, efternavn, vej navn, vej nr, post nr, by, etc.). Med et sådan design bliver latens tiden et stort problem, stabiliteten kun værre og vores koordinerings og kompensations problem meget større. Der må mangle noget til at guide os til et bedre service design!
I næste blog post skal vi se på hvordan man man kan integrere services i en distribueret verden og hvilken betydning det har for granulariteten af vores services og hvordan vi integrerer dem. Indtil da, ser jeg frem til jeres kommentarer, spørgsmål og ideer 🙂
English version: http://www.tigerteam.dk/2014/micro-services-its-not-only-the-size-that-matters-its-also-how-you-use-them-part-1/
Man kan sige, at du tager et langt proceduralt kodesample, fjerner atomiciteten og splitter den i atomer – og dermed har du balladen. Du fjerner den oprindelige “sikkerhed” for at enten skete alt – eller også skete intet. (I situationstegn, fordi det i høj grad kan diskuteres om det er atomic, hvis det involverer dtc :-)).
Nu har jeg snydt og set dit foredrag omkring SOA, men vi bokser i høj med den her slags problemstillinger i Xena:
* “Brugeren har trykket på “Fakturer” og forventer at han får en udskrift…”
-> Hvad gør vi?
Siger vi:
* “Du kan rende os… du får rapporten når det passer os?” (og krydser fingre for at han ikke skifter skærmbillede, lukker browseren).
Siger vi:
* “Javel!” og lever med multiple servicekald i en lang procedural kodestreng fra helvede?
Eller laver vi noget temmelig kompliceret med hensyn til call-backen, noget med nogle notifikationer og/eller print-kø widget?
Der er fordele og ulemper ved det hele:
1 er rimelig sikker – har nem retry (fejl-køer eller lign.), men overvågning bliver lige pludselig vigtig, fordi klienten venter og vi har ikke uanet tid.
2 fungerer måske 99 ud af 100, men fejler så nr. 100, spiser ressourcer, er ualmindelig svær at skalere (DTC) osv.
3 giver høj kode kompleksitet, hvor det kan være svært for en ny udvikler at fatte, hvor han skal kigge fordi alle dependencies peger bagud… Så den kræver forholdsvis erfarne udviklere og er nem at fucke op.
Størrelsen af løsningen spiller også en rolle – er det en one-off løsning, som skal fungere næste weekend og så bliver den kasseret derefter (fx til et arrangement) eller er det dit levebrød de næste 20 år? Hvor mange udviklere er I på opgaven (eller er der mange teams?) Hvilke dependencies har vi til andre systemer – legacy såvel som closed-source black-box serverdimser (jeg kigger på dig: XSLT Ecrion reportserver).
En masse strøtanker – jeg ved godt, hvad jeg ville vælge i en større kompleks løsning, som skal vedligeholdes de næste mange år 😉
Jeg er enig i at en synkron løsning hvor alt sker sekventielt er nemmere at implementere og forstå. Og nogen gange er det også den løsning der er bedst. Typen af løsning, levetiden, time to market er alle med til at afgøre hvor meget vi skal gøre ud af en given løsning (skal den testes grundigt, skal vi skrive unit tests, skal vi designe den ordenligt eller skal vi bare flække noget spaghetti kode sammen).
Mht. til din løsning med fakturaer, vil løsningen afhænge af hvordan usecasen og bruger feedbacken skal være. Personligt ville jeg foretrække en kø baseret løsning. Men det kræver at UI’en bliver designet derefter. Jeg har tidligere været med til at implementere et web baseret fakturerings system hvor fakturerings ønsket bliver sendt som en command over en kø. UI’en skifter bagefter til en oversigts side, hvor man kan se at fakturaen er ved at blive sendt (man kan også se andre fakturaer og deres status). På den måde er UI’en designet til at indikere at feedback på faktuering ikke er umiddelbar, men tager lidt tid og den følger et flow.
Via callback bliver status løbende opdateret opdateret (kan både ske som pull eller push). Fordelen ved den mekanisme er at når vi først har fakturerings kommandoen gemt i køen kan vi nemt gen-prøve faktureringen upåagtet at evt. understøttende services ikke er tilgængelige eller hvis ens database fejler under transaktionen (pga. netværks fejl, server genstart, timeout, deadlock, etc.).
Alt omkring fakturering skete over køer (i flere stadier også kendt som Staged Event Driven Architecture eller SEDA), men mange andre ting, som f.eks. oprettelse af kunder, skete synkront da der kun var en enkelt service involveret og arbejdsformen bedre matchede CRUD paradigmet.
[…] Danish version: https://qed.dk/jeppe-cramon/2014/02/24/microservices-det-er-ikke-kun-stoerrelsen-det-er-vigtigt-det-e… […]
[…] […]
[…] […]
[…] Del 1 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du… Del 2 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem Del 3 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem […]
[…] Del 1 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du… Del 2 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem Del 4 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem […]
[…] Et rigtig fint indlæg af Adrian, hvor han fortalte om Netlfix tilgang til produkudvikling, DevOps og Microservices og hvordan man gennem tiderne havde sagt at det ikke kan virke og senere at det kun ville virke for Netflix fremtil i dag hvor flere forsøger at gå i samme retning. Adrian kom ikke detaljeret ind på Microservices ud over at sige at man bør læse om Bounded Context i Domain Driven Design bogen af Eric Evans, da en Microservice bør alignes med en Bounded Context. Jeg er enig i den betragtning, men jeg synes samtidig at der mangler noget mere guidance, så vi undgår microservices der kalder microservices, der kalder microservices. Men med tiden skal det nok komme. Hvis du er nysgerrig kan du læse mere i min blog serie om Microservices. […]
[…] online. Hvis du er ny til SOA/Microservices og/eller DDD kan jeg anbefale at læse min Microservice serie samt se Udi Dahans keynote […]