JavaScript bliver som udgangspunkt afviklet i en enkelt tråd og for stadig at sikre en reagerende grænseflade kan og bør de fleste input/output-kald afvikles asynkront:
- Http forespørgsler
- Filesystem API
- Database API (IndexedDB og WebSQL)
Ja, det lyder som om at det kun er engang imellem at vi skal bevæge os ud i asynkrone kald, men fordi at IO ofte er i bunden af de fleste kalde-stakke, ender det med at behovet for asynkron kode bobler op og påvirker hele applikationen.
Men ofte er der behov for at udføre noget kode efter at de asynkrone kald er overstået. I gamle dage foregik dette ved at man sendte en JavaScript-funktion med ind, som kaldet så kunne udføre efter at den asynkrone del var overstået (også kaldet en callback funktion).
Der er flere problemer med modellen:
- Funktionernes parametre bliver forurenede med callback funktioner, der er nemlig ofte hele tre callbacks; en hvis det asynkrone kald gik godt, en hvis det gik galt, samt en der blot fortæller at det asynkrone kald er overstået.
- Da man ofte ønsker at sammenkæde flere asynkrone kald kan de nestede kald blive noget uoverskuelige – populært kaldet callback-hell. Eksempel:
ajax('/applicationData', {}, function() { ajax('/customer', { customerId: 1 }, function (customer) { ajax('/order', { orderId: customer.orderId }, function (order) { showOrderDetails(order); }, function () { showError('Unable to get order'); }); }, function () { showError('Unable to get order'); }); }); - Synkronisering er svært; forrige eksempel hentede først en ordre, derefter en kunde. Kører man begge kald på samme tid, for at få et hurtigere svar til brugeren, skal showOrderDetails() først køre når to forskellige callback-funktioner er kørt – det er ikke nemt uden en synkroniserings struktur som fx. promises.
Promises
En promise er et simpelt objekt der kan returneres fra asynkrone funktioner. Det specielle er at det kan skifte tilstand en gang, og kun en gang. Den kan enten være ventende (pending), opfyldt (fulfilled) eller afvist (rejected):
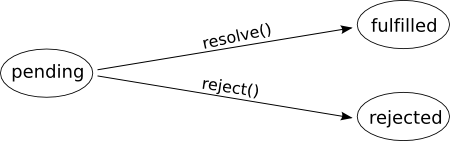
På objektet findes der en funktion der tager to callbacks, en der bliver kaldt hvis det asynkrone kald gik godt, og en der bliver kaldt hvis der skete en fejl:
promise.then(onFulfilled, onRejected)
Ydermere returnerer then() selv en promise.
Overstående beskrivelse holder dog ikke altid, der er mange forskellige biblioteker og frameworks der gennem tiden har implementeret promises forskelligt, det har ført til at der er blevet skrevet et antal specifikationer som man så kan erklære om man overholder eller ej. Overstående er som beskrevet i Promises/A+ specifikationen.
Hvis vi går ud over specifikationen og kigger på faktiske implementationer består de typisk i en mekanisme til at skabe sine egne promises.
Det der som regel sker er at man først skaber et objekt, typisk kaldet en deferred der så enten producerer den egentlige promise, eller også udstiller den promise-funktionerne selv. Førstnævnte er at foretrække, da verdenen uden for det asynkrone kald dermed ikke kan komme til at skifte tilstanden.
Dermed kan (for nu er vi uden for det specificerede) API’et til et promise-bibliotek se sådan her ud:
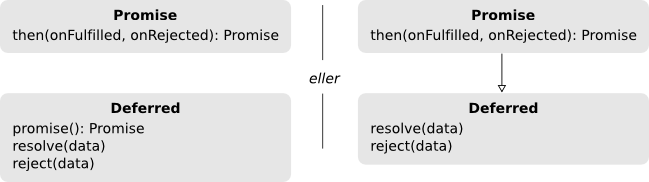
Og koden fra før kan omskrives ved brug af promises, og dermed fjerne det dybe træ, samt forenkle en hel del:
ajax('/applicationData', {})
.then(ajax('/customer', { customerId: 1 }))
.then(function (customer) {
return ajax('/order', { orderId: customer.orderId });
}, function () {
showError('Unable to get order');
}).then(function (order) {
showOrderDetails(order);
});
Hvis vi i ovenstående eksempel antager at kunde og ordre-kaldet ikke er afhængige af applikations-data kaldet, kan vi endda mindske brugerens ventetid ved at udføre de to første forespørgsler parallelt ved hjælp af hjælpefunktion der samler flere promises til en:
var appData = ajax('/applicationData', {});
var order = ajax('/customer', { customerId: 1 }).then(function (customer) {
return ajax('/order', { orderId: customer.orderId });
});
Promise.all(appData, order).then(function (order) {
showOrderDetails(order);
}, function () {
showError('Unable to get order');
});
Ønsker man at benytte promises skal man i dag benytte sig af et bibliotek men browserne er så småt begyndt at understøtte det fra fødslen. De biblioteker der er, giver dog også mange andre interessante promise relaterede funktioner såsom notifikation om hvor langt en asynkron opgave er kommet, en forsinket promise der bliver opfyldt efter et specificeret stykke tid og konvertering af andre bibliotekers promises til det aktuelle biblioteks.
Nævneværdige promise-biblioteker er Bluebird, Q og D. Bemærk at jQuery har noget der ligner, men ikke rigtig overholder specifikationen.
Dette var en lille introduktion til promises som jeg håber kan blive fundament for nogle fremtidige posts. Benytter du allerede promises i dag, har du planer om det – eller foretrækker du måske koden med almindelige callbacks?
Super godt indlæg som altid. Giver mig helt sikkert lyst til at kigge lidt mere på promises.
Mange tak 🙂
Super godt indlæg som altid. Giver mig helt sikkert lyst til at kigge lidt mere på promises.
Mange tak 🙂
Super indlæg! Promises er fantastiske til at gøre api’er væsentlige simplere og for .NETere er Task Parallel Library (med Task typen) også en uundværlig ven når concurrent og parallel eksekvering er påkrævet.
Med generators i ES6 eller 7 bliver promises endnu mere interessant da man vha. generators kan få en opførsel som det bl.a. kendes fra F#s async, Clojures core.async og C#s async/await. Med task.js (https://github.com/mozilla/task.js) biblioteket fra Mozilla kan man f.eks. skrive følgende og koden efter [foo, bar] vil først eksekvere når de promises som read(…)-kalende resulterer i er blevet resolved. Bemærk også destructuringen af foo og bar som er endnu en af de mange fede ES6 features som vi må vente i længsel på 🙂
spawn(function*() {
try {
var [foo, bar] = yield join(read(“foo.json”),
read(“bar.json”)).timeout(1000);
render(foo);
render(bar);
} catch (e) {
console.log(“read failed: ” + e);
}
});
Tak for feedback.
Jeg jeg kender det fra C# – er stor fan af yield, det bliver fedt at få i javascript.
Og spændene hvordan det bliver at debugge i browseren 🙂
Super indlæg! Promises er fantastiske til at gøre api’er væsentlige simplere og for .NETere er Task Parallel Library (med Task typen) også en uundværlig ven når concurrent og parallel eksekvering er påkrævet.
Med generators i ES6 eller 7 bliver promises endnu mere interessant da man vha. generators kan få en opførsel som det bl.a. kendes fra F#s async, Clojures core.async og C#s async/await. Med task.js (https://github.com/mozilla/task.js) biblioteket fra Mozilla kan man f.eks. skrive følgende og koden efter [foo, bar] vil først eksekvere når de promises som read(…)-kalende resulterer i er blevet resolved. Bemærk også destructuringen af foo og bar som er endnu en af de mange fede ES6 features som vi må vente i længsel på 🙂
spawn(function*() {
try {
var [foo, bar] = yield join(read(“foo.json”),
read(“bar.json”)).timeout(1000);
render(foo);
render(bar);
} catch (e) {
console.log(“read failed: ” + e);
}
});
Jeg er ved at lave en golang ( http://golang.org/ ) pakke, der hedder sdom (kode er ikke tilgængelig, endnu).
Den pakke er den interne repræsentation af Document Object Model.
Jeg laver den fordi jeg vil lave en fokuseret webcrawler og tilhørende meget emne-specifikke søgemaskine.
HTML5 parser pakken ‘html’ fra “code.google.com/p/go.net/html/” skal forkes så den bruger sdom pakkens Node type i stedet for – senere kan så skrive koden lidt om så den bruger en W3C standardiseret DOM pakke.
Jeg har kigget på både DOM Core (Level 3) og den nuværende DOM (Level 4): http://dom.spec.whatwg.org/
I DOM level 4 spec’en, der er under udvikling er promises (tidligere futures) beskrevet en lille smule her: http://www.w3.org/TR/2013/WD-dom-20131107/#promises , og jeg tænkte at den ville jeg kigge på lidt senere.
Din artikel beskriver meget godt hvad der foregår, og som jeg ser det kan jeg rimelig nemt implementere det i Go, da jeg kan afvikle promise kode ved at køre dem som et blokerende kald i go routiner sammen med channels.
Nogen har lavet noget om Hoare’s CSP og hvordan hvert problem kan løses i Go med go routine(r) og channel(s): http://godoc.org/github.com/thomas11/csp
Go koden er i et Git repo på http://github.com/thomas11/csp
Hej Lars,
Kender ikke meget til go, men det lyder sejt – vil det sige at din Go crawler skal kunne afvikle javascript, eller er det bare strukturen der går igen i Go?
“Kender ikke meget til go, men det lyder sejt – vil det sige at din Go crawler skal kunne afvikle javascript, ”
Den er som alle web crawlere slet ikke interesseret i Javascript, da de normalt ikke bidrager med indhold.
HTML dokumentet parses ind i et DOM træ af en HTML5 parser, men JavaScript køres ikke
Der findes en Javascript fortolker skrevet i Go sproget, der hedder otto:
* Otto dokumentation: http://godoc.org/github.com/robertkrimen/otto
* Otto kildekode: https://github.com/robertkrimen/otto
En mere færdigudviklet udgave af otto ville jeg kunne limes sammen med DOM træet, sådan at man rent faktisk kunne køre Javascript – hvis man ville.
Jeg lader HTML5 parseren få en “klip alle former for scripts ud” mulighed. I starten er den indstilling altid “true”, og kan ikke ændres (den er hard coded). Idéen kommer fra jsoup: http://jsoup.org/cookbook/cleaning-html/whitelist-sanitizer
Det gør at man kan skrive kommentarer i ren HTML og så lade HTML5 parseren si XSS angreb ud ved simpelthen at droppe alt javascript på gulvet, så snart HTML parseren ser javascript kode i den indtastede HTML kommentar.
“… eller er det bare strukturen der går igen i Go”
Jeg er ved at lave det der i W3C terminologi kaldes for en DOM implementation i Go.
Ifølge DOM Core standarden kan man stadig hævde at være DOM standard kompatibel, selv om support for Javascript ikke implementeres i DOM træet. “Events” hører f.eks. ikke til en DOM Core implementation.
Jeg glemte måske nok lige at skrive at jeg på den lange bane vil jeg gerne implementere support for CSS, Events, XPath, XML, Javascript og promises i en DOM implementation,
Det var derfor jeg var interesseret i promises til at starte med.
Jeg kommer nok til at kende W3C standarderne meget godt hen ad vejen.
Drømmer selv lidt om den dag hvor Google-crawleren kan forstå noget simpelt javascript. Du må jo sandboxe det så du ikke rammer ind i XSS angreb m.v.
Det lyder som en stor opgave, men den kan nok deles meget op i features – som fx. en CSS DOM?
Gik engang selv og drømte om at lave en DOM hvor man kunne bruge CSS-style queries til at hente indhold ud på samme måde som jQuery. Det er nemt at teste i browseren – og så er API’et IMO rigtigt godt med method chaining og at den altid arbejder med collections.
Har tidligere arbejdet med HtmlAgilityPack der tilbyder traversering vha. XPath men ikke CSS-style queries.
Jeg er ved at lave en golang ( http://golang.org/ ) pakke, der hedder sdom (kode er ikke tilgængelig, endnu).
Den pakke er den interne repræsentation af Document Object Model.
Jeg laver den fordi jeg vil lave en fokuseret webcrawler og tilhørende meget emne-specifikke søgemaskine.
HTML5 parser pakken ‘html’ fra “code.google.com/p/go.net/html/” skal forkes så den bruger sdom pakkens Node type i stedet for – senere kan så skrive koden lidt om så den bruger en W3C standardiseret DOM pakke.
Jeg har kigget på både DOM Core (Level 3) og den nuværende DOM (Level 4): http://dom.spec.whatwg.org/
I DOM level 4 spec’en, der er under udvikling er promises (tidligere futures) beskrevet en lille smule her: http://www.w3.org/TR/2013/WD-dom-20131107/#promises , og jeg tænkte at den ville jeg kigge på lidt senere.
Din artikel beskriver meget godt hvad der foregår, og som jeg ser det kan jeg rimelig nemt implementere det i Go, da jeg kan afvikle promise kode ved at køre dem som et blokerende kald i go routiner sammen med channels.
Nogen har lavet noget om Hoare’s CSP og hvordan hvert problem kan løses i Go med go routine(r) og channel(s): http://godoc.org/github.com/thomas11/csp
Go koden er i et Git repo på http://github.com/thomas11/csp
Hej Lars,
Kender ikke meget til go, men det lyder sejt – vil det sige at din Go crawler skal kunne afvikle javascript, eller er det bare strukturen der går igen i Go?
Jeg glemte måske nok lige at skrive at jeg på den lange bane vil jeg gerne implementere support for CSS, Events, XPath, XML, Javascript og promises i en DOM implementation,
Det var derfor jeg var interesseret i promises til at starte med.
Jeg kommer nok til at kende W3C standarderne meget godt hen ad vejen.
Drømmer selv lidt om den dag hvor Google-crawleren kan forstå noget simpelt javascript. Du må jo sandboxe det så du ikke rammer ind i XSS angreb m.v.
Det lyder som en stor opgave, men den kan nok deles meget op i features – som fx. en CSS DOM?
Gik engang selv og drømte om at lave en DOM hvor man kunne bruge CSS-style queries til at hente indhold ud på samme måde som jQuery. Det er nemt at teste i browseren – og så er API’et IMO rigtigt godt med method chaining og at den altid arbejder med collections.
Har tidligere arbejdet med HtmlAgilityPack der tilbyder traversering vha. XPath men ikke CSS-style queries.
[…] my previous post in Danish I looked at how to perform asynchronous calls by using promises. Now the time has […]
[…] my previous post in Danish I looked at how to perform asynchronous calls by using promises. Now the time has […]
[…] mit tidligere indlæg kiggede jeg på hvordan man kunne udføre asynkrone kald ved hjælp af promises. Nu er tiden kommet […]
[…] mit tidligere indlæg kiggede jeg på hvordan man kunne udføre asynkrone kald ved hjælp af promises. Nu er tiden kommet […]