Med Elasticsearch har man en hel palette af måder at strukturere sine fritekstsøgninger på, lige fra simple termer til advancerede geografiske søgninger.
Den grundlæggende teknologi der muliggør dette finder man nederst i teknologistakken. Her ligger et, i IT sammenhæng, nærmest antikt produkt Lucene fra 1999, skrevet i Java men oversat til mange andre sprog.
Lucene er en ren søgemaskine, dens primære rolle er at bygge et indeks, kaldet inverted index der mest af alt ligner det man finder bagerst i en bog:
| Ord | Dokument nummer |
| amet | 2 |
| doler | 2 |
| ipsum | 1,2 |
| lorem | 1 |
| sit | 2 |
I det her eksempel indekseres to tekster
Lucene henter, gemmer og manipulerer kun én enhed; dokumenter. Hvert dokument består af et antal felter i én dimension, der er ingen niveauer.
Hvert felt består af et navn, en værdi samt en type fx. string, long og man har mulighed for at vælge om der skal bygges et indeks over feltet eller ej, samt om værdien selv skal gemmes sammen med dokumentet eller ej. Det vil sige at i princippet kan et dokument være helt tomt og kun bestå indekserede data som i ovenstående eksempel, men det ville ikke være særligt brugbart, for det eneste man ville få at vide ved søgning på “amet” er at ordet befinder sig i dokument nummer 2.
Kigger man på Elasticsearch’ API, kan man gemme, indeksere og hente en næsten vilkårlig dyb struktur og det er et godt eksempel på hvordan de har integreret Lucene med de begrænsninger det medfører – og lagt de funktioner man forventer af en moderne dokumentorienteret database ovenpå.
For at få hierarkiske strukturer til at passe ned i Lucene foretager Elasticsearch en udfladning af data:
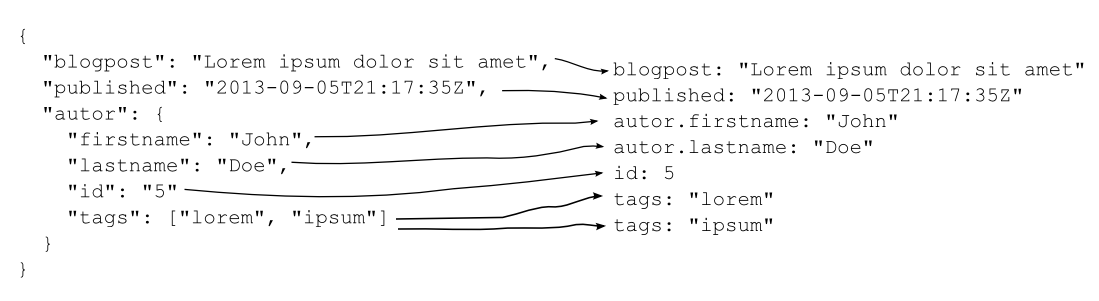
Mapning fra hieraki til flad struktur, bemærk at der i et dokuments feltnavne godt kan være gengangere.
Næste trin er så at kunne genskabe originaldokumenter igen efter fremsøgning. I princippet kunne man godt gemme de enkelte felters værdier og så forsøge at konstruere et fuldt dokument ud fra disse – det ville kræve et ret godt schema; hvis der fx kun er et tag, vil man ikke kunne skelne mellem om tagget er en streng eller et array.
I stedet gemmer Elasticsearch det komplette dokument i et dedikeret felt kaldet _source, det betyder at den blot skal aflevere dokumentet fra _source ved hentning, og alle andre felter kan indeholde rene indekserede værdier, kun fastholdt i det omvendte indeks.
Desuden har Lucene indbygget komprimering pr. felt – forsøgte man at komprimere de relativt få data der er i hvert felt i eksemplet vil der ikke være nogen gevinst, i værste tilfælde en forøgelse af dataene. Men med det datamæssige større _source felt er der god komprimeringsevne.
På den måde kan med ElasticSearch opnå kraftfuld fritekstsøgning, samtidig med at man kan forvente at ens data kommer ud i præcis den samme struktur man oprindeligt gemte.