Noget der virkelig har givet NoSQL medvind er behovet for skalering; data mængder har det med at vokse. Uanset om der er tale om en lille opstartsvirksomhed med ambitioner om international succes eller blot almindelig tilvækst af data, så er der behov for at kunne skalere. Ydermere kan behovet opstå pludselig.
Elasticsarch er fra starten forberedt på skalering med henholdsvis sharding og replikering; selv hvis ens cluster fra starten kun består af én node, er der plads til at gro.
Noder i Elasticsearch svarer til instanser – der kan godt være flere på en maskine, men som regel har man en node pr. maskine. Hver node har som udgangspunkt to roller, de agerer både klient og server. Klientdelen tager sig af at aggregere data for operationer på tværs af clusteret og det giver reelt ingen forskel hvilken klient man går til. I nogle scenarier kan det endda give mening at fratage visse noder rollen som server og kun lade dem være klient – endnu en måde at skalere på.
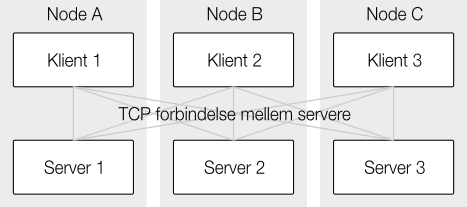
Sharding
Når man opretter et nyt indeks med standardindstillinger på et cluster bestående af bare én enkelt node ser det sådan her ud:
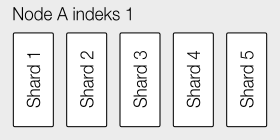
Man får altså en underlæggende datastruktur der består af fem shards og det er denne enhed der er den primære skaleringsmekanisme i Elasticsearch. Hvis man tilføjer endnu en node, og med Elasticsearch betyder det bare at starte den, vil clusteret straks gå i gang med at balancere data på de to noder – en operation der er ganske let da det er det hele indeks der skal flyttes, det er reelt en simpel rå flytning – der er ingen genindeksering af data eller lignende:
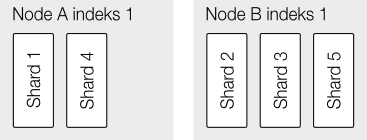
Når man så gemmer et nyt dokument er der en hashfunktion der afgør hvilken shard et dokument ender op på. Hashfunktionen kan i øvrigt overskrives med ens egen rute hvilket kan være nyttigt hvis man har data der af natur er meget separate – det kunne være brugerdata der kun er relevante for brugeren selv. Der kan stadig forespørges på tværs af brugere, men data for en enkelt bruger skal kun fremsøges på en bestemt shard.
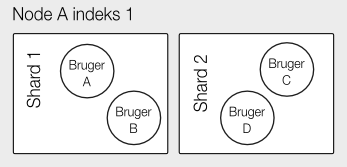
Replikering
En anden ting der er på nye indeks er replikering, der som standard er sat til to. Med denne indstilling vil Elasticsearch forsøge at sikre at skrevne data findes i to forskellige indeks på to forskellige noder (hvis der da er to til rådighed). Operationen er synkron, så hvis ellers ens cluster er sundt og rask kan man altid være sikker på at man kan finde ens data igen – selv ved en fatal hardware-fejl.
Men replikering handler ikke kun om sikkerhed; ud over at det faktisk giver øget belastning ved tilføjelse af nye dokumenter, vil det give øget ydelse ved søgning, da der er flere maskiner der kan kigge i det samme indeks. Hvor sharding er noget der ikke kan ændres når man først har oprettet et indeks, så kan repliering justeres løbende så man kan med visse data vælge at skrive usikkert for at få høj skrive-ydelse, og så senere tilføje replikering for at få høj læse-ydelse.
Som det ses så har man rig mulighed for at skalere og med den, fra starten, indbyggede overallokering handler det næsten kun om at starte flere maskiner for at kunne klare en større belastning. Der er stadig mange ting der kan gå galt når man distribuerer, men Elasticsearch har gjort det let at komme i gang.