Med Lucene som fundament har man med ElasticSearch naturligvis en førsteklasses søgemaskine. Lucenes modenhed er en stor fordel når vi kigger på featuresættet, men med i prisen er der også en del legacy-baggage. Elasticsearch abstraherer ikke Lucene væk – dens JSON-baserede REST-interface giver adgang til alle Lucenes funktioner.
Men Elasticsearch er ikke bare en indpakning af Lucene – derudover indeholder den et lag der søger for distribuering og aggregering.
Søgning
Når en søgning skal startes, kan det foregå på en hvilken som helst node i ens cluster og de fleste klienter kan finde ud af at skifte imellem de tilgængelige noder ud fra fejlmarginer og svartider. Den node man rammer bliver den koordinerende node for den pågældende søgning (medmindre man i form af preference-parameteren vælger at en anden node skal være koordinerende).
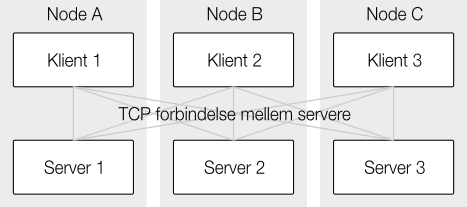
Indexes er som standard opdelt i fem shards. En simpel hash-funktion angiver hvilken af disse shards et dokument havner på og derfor skal søgninger også som udgangspunkt besøge alle shards. Hash-funktionen kan seedes ved at tilføje en routing-parameter i forbindelse med indeksering hvis en gruppe af dokumenter har et naturligt tilhørsforhold. Hvis dette tilhørsforhold også gælder for en søgning kan vi også her bruge routing og dermed undgå at skulle besøge op til fire af de fem shards. Et typisk eksempel er brugerdata, hvor man lader en enkelt brugers data havne på den samme shard fordi at man i mange tilfælde kun skal bruge disse.
Noden udfører først en forespørgselsfase imod en udgave af hver shard af et index, hvis en shard er replikeret vil den round-robin skifte imellem hver kopi. For hver shard produceres der en liste over matchende dokumenter som den koordinerende node sammensætter til en enkelt samlet liste.
Listen reduceres til det ønskede antal dokumenter og der efter kører anden fase hvor de egentlige dokumenter bliver hentet fra hver enkelt shard og returneret som resultat på søgningen.
Aggregeringer
Ud over at returnere dokumenter kan Elasticsearch også lave grupperering beregning på dokumenter med en map-reduce lignende struktur. Gruppering af dokumenter foregår med et koncept kaldet buckets og beregninger med et kaldet metrics.
Ønsker vi eksempelvis at se hvad det mest brugte ord er på twitter, kan vi lade Elasticsearch indeksere alle tweets – hver tweet kunne se sådan her ud:
{
text: "Wicked day yesterday"
}
Vi lader så Elasticsearch tælle or ved at udføre en terms-aggregering:
{
"aggs" : {
"antal-ord" : {
"terms" : {
"field" : "text"
}
}
}
}
Og her et rigtigt top 3 fra Twitter:
{
"aggregations": {
"antal-ord": {
"buckets": [
{
"key": "rt",
"doc_count": 5482454
},
{
"key": "t.co",
"doc_count": 4754400
},
{
"key": "http",
"doc_count": 4735296
}
]
}
}
}
Kun et lille eksempel på hvad aggregeringer kan bruges til. Aggregeringer kan yderligere kombineres med andre aggregeringer og dermed give mange muligheder for at lave komplekse udtræk og dataanalyser.
Elasticsearch har med Lucene som fundament ramt en rigtig god løsning på problemet søgning. Derudover er det en ret avanceret dataanalyseplatform der allerede på nogen punkter kan give realtidsvar på spørgsmål der hidtil er blevet besvaret af tunge batch-processeringer.
Produktet er stadig ungt, og værktøjsunderstøttelsen i sin spæde start, men økosystemet allerede ret omfattende, og som rent open-source produkt er det nemt at udvikle til.