Del 1 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem
Del 2 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem
Del 3 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem
I del 3 så vi at for at sikre en højere grad af autonomi for vores services, har vi behov for at undgå (synkron) 2 vejs kommunikation mellem services og i stedet bruge 1 vejs kommunikation.
En højere grad af autonomi går hånd i hånd med en lavere grad af kobling. Jo lavere kobling, vi har, desto sjældenere bliver vi nødt til at håndtere kontrakt og data versionering.
Vi øger også vores services stabilitet – svigt i andre services påvirker ikke direkte vores services evne til at reagere på stimuli.
Men hvordan kan vi få noget arbejde udført, hvis vi kun bruger 1 vejs kommunikation? Hvordan kan vi få data tilbage fra andre tjenester på denne måde? Det korte svar er, at det kan du ikke, men med veldefinerede service boundaries (afgrænsinger) har du, i de fleste tilfælde, ikke behov for at kalde andre services direkte fra din service for at få data tilbage.
Service boundaries (afgrænsning)
Hvad er en service boundary (afgrænsning)?
Det er dybest set et ord, der bruges til at definere de forretnings-data og den forretnings-funktionalitet en given service er ansvarlig for. I SOA: synkron kommunikation, data ejerskab og kobling afdækkede vi service principper såsom boundaries og autonomi i detaljer.
Boundaries afgør hvad der er indenfor og udenfor en service. I del 2 brugte vi aggregate mønsteret til at analysere, hvilke data hørte til i LegalEntity (juridisk enhed) servicen.
I tilfældet med servicen LegalEntity indså vi, at sammenhængen mellem en juridisk enhed og dens adresser hørte tæt sammen, fordi en juridisk enhed og dens tilhørende adresser blev skabt, ændret og slettet sammen. Ved at erstatte to services (LegalEntity Service og Address Service) med én (LegalEntity Service) fik vi fuld selvstændighed/autonomi for LegalEntity servicen, hvorved vi kunne undgå behovet for orkestrering af opdateringer, samt vi undgik at skulle håndte alle de fejl-scenarier, der kan opstå når man orkestrerer data muterende kald mellem services (LegalEntity servicen og Address servicen).
I tilfældet med LegalEntity servicen var koblings problematikken let at løse, men hvad sker der, når vi har et mere komplekst sæt af data og relationer mellem disse data? Vi kunne bare samle alle disse data i een Service og derved undgå problemet med data mutations kald på tværs af process grænser (dvs. forskellige tjenester, der hostes i andre OS processer eller på forskellige fysiske servere). Problemet med denne tilgang er, at dette hurtigt bringer os ind monolit territorium.
Slørede boundaries (grænser) – monolittens glidebane
Et af problemerne med monolitter er slørede boundaries (grænser). Monolitter har en tendens til at påtage sig for mange ansvarsområder i form af data og funktionalitet / logik.
Det er for nemt bare at kalde andre funktioner, komponenter eller joine med andres tabeller for at blive hurtig færdig.
Smagen af en monolit føles sød, især i starten af et projekt, når problemerne er færre og kompleksitet er lavere.
Med en monolit kan du:
- Tage fordel af lokalitet
- Udføre in-memory kald og undgå distribuerede transaktioner
- Kan udføre joins med andre komponenters SQL tabeller, fordi de ligger i den samme DB/Schema
- Tage fordel af udviklingsværktøjer (IDE’s) og bruge funktioner såsom refactoring, code completion og kode søgning
Bagsiden af denne mønt er risikoen for højere kobling og lavere samhørighed (cohesion). Monolitter har tendens til at danne en glidebane, hvor de langsomt vokser sig større og større, fordi de påtager sig mere og mere ansvar, oftest fordi det er nemt blot at klistre ny funktionalitet ovenpå den allerede eksisterende data og logik.
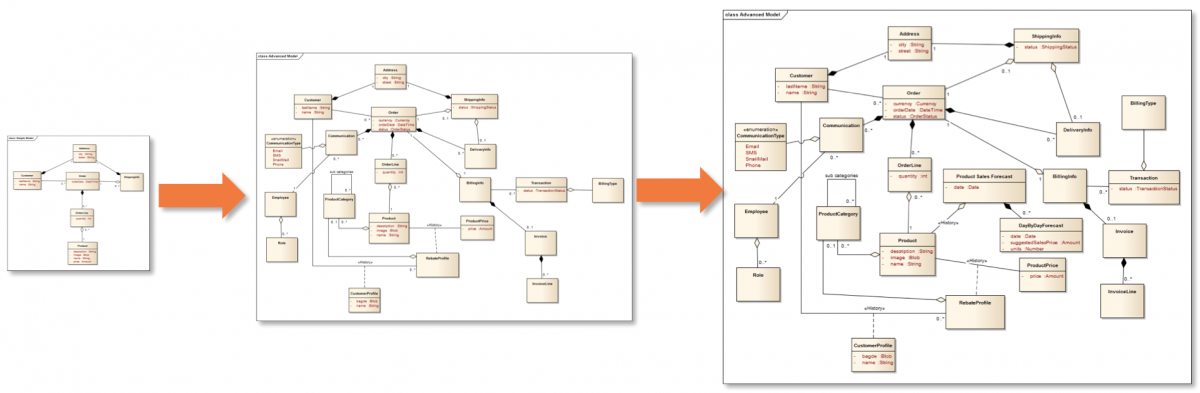
Stille og roligt vokser vores data modeller i størrelse til de tilsidst bliver forvirrende og rodede
Det er det jeg plejer at kalde monolittens glidebane:
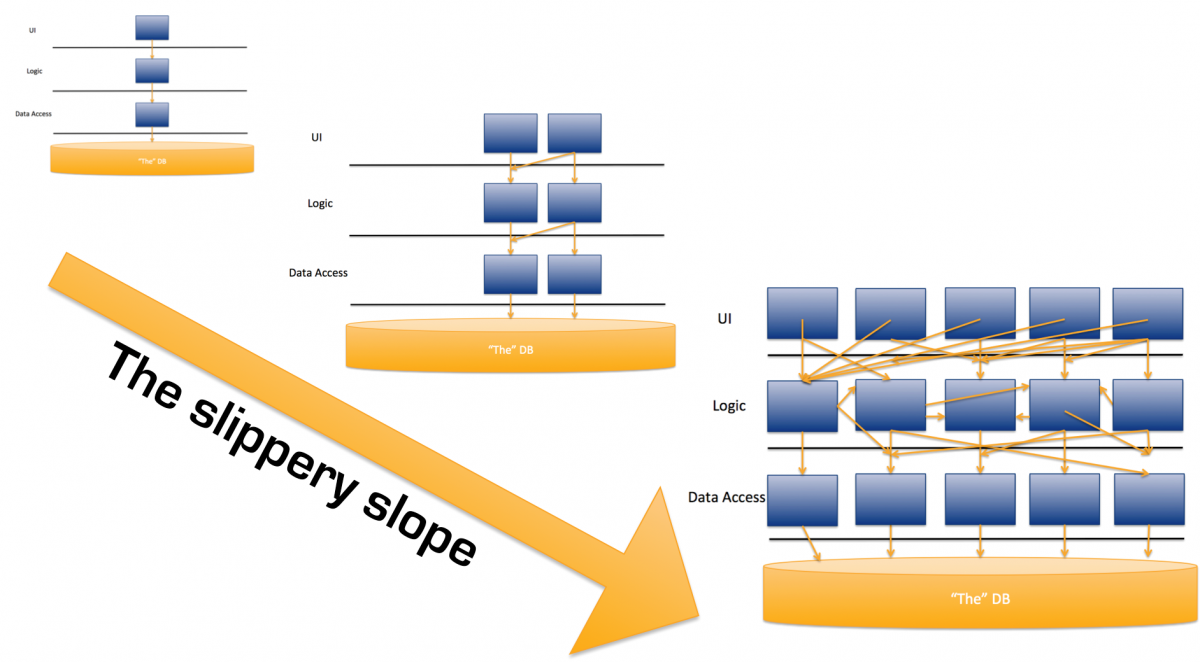
Monolittens glidebane som kompleksiteten vokser
Med monolitter risikere vi at løbe ind i flere ulemper, såsom:
- Det er svære at tilpasse sig ny teknologi – du bliver oftest nød til at omskrive hele monolitten for at bruge et nyt framework/sprog/teknologier (eller benytte komplicerede løsninger som OSGi)
- Lav Genbrugelighed
- Funktionaliteten af en del kan ikke genbruges alene
- Langsomt leverance tog
- Indførelse af en ny funktionalitet kræver ofte koordinering med andre grupper så alt kan blive leveret på samme tid (alt eller intet leverance)
- De vokser og vokser og vokser mht størrelse og ansvarsområde
- Højere og højere kobling
- Højere og højere vedligeholdelsesomkostninger over tid
- Start af monolitten tager ofte lang tid
- Test af monolitten tager ofte lang tid
- Monolitten stiller høje krav til den mentale kapacitet der kal til for at holde hele monolit i hovedet
- Lavere pålidelighed
- Svigt i een komponent kan potentielt bringe hele monolit ned (fx på grund af en OutOfMemoryException)
Du kan designe monolitter med interne services / komponenter der har løs kobling og veldefinerede boundaries, men fra mine 20 års erfaring er det sjældent tilfældet. En stor gang spaghetti er desværre normen.
Integration med en bunke webservices
Det er min erfaring at mange organisationer nærmer SOA ved at placere (web) services oven på eksisterende monolitter. Dette kan helt sikkert giver mening som een måde at åbne gamle monolitter op og dermed få en højere grad af genanvendelse.
Problemet med dette er: De fleste monolitter har udviklet sig til at indeholde mange forskellige forretningsområder (business capabilities). Det betyder, at virksomhederne er endt med at have multi-master systemer, hvor flere systemer besidder lignende eller de samme business data, og der er ingen enkelt kilde med det rigtige svar (single source of truth).

Monolitisk integration med en bunke webservices
Hvis vi bare tager de eksisterende monolitter og skærer dem op i små (mikro) services, så er vi også nødt til at beskæftige os med den interne kobling i monolitterne. Den interne kobling er typisk resultatet af arv, direkte metode kald, SQL joins, osv. Hvis dette er vores tilgang til at skabe (mikro) service så er vi gået fra slemt til værre.
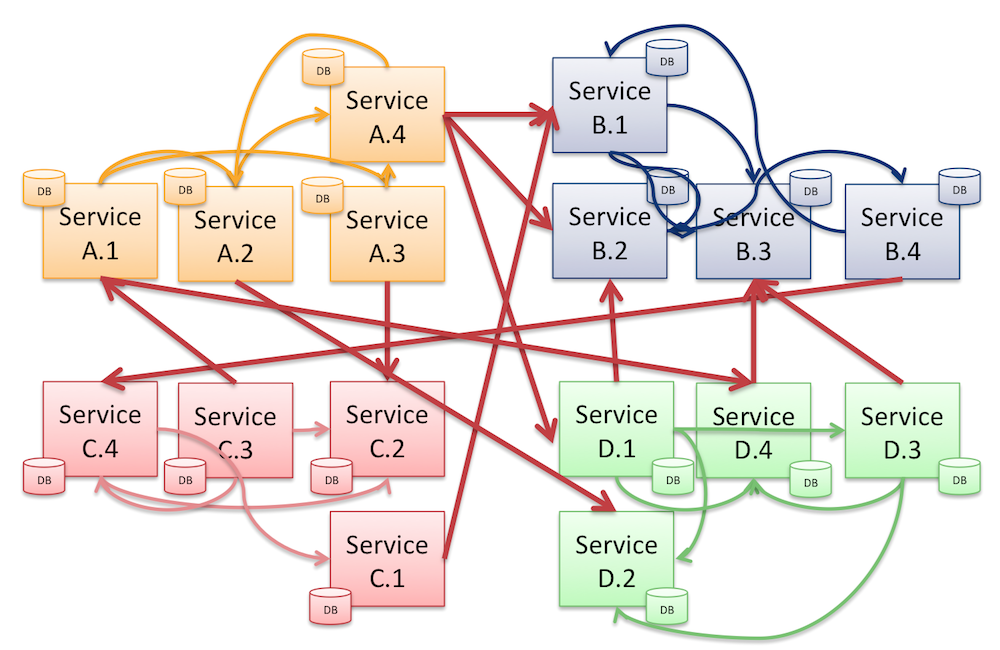
Monolitter delt op i microservice på den værst tænkelig måde
Alt dette er et resultat af svage eller slørede service-boundaries. Vi får services, der er trængende og grådige med hensyn til andre services data og funktionalitet. Efter min mening er dette ikke løs kobling, det er det modsatte.
Hvordan definerer vi service boundaries (grænser)
Når man bygger nye services eller definerer nye service baseret på gamle monolitter, er vi nødt til at bruge tid på at definere grænserne for vores nye services, så vi (langsomt – i tilfælde migration) kan komme væk fra at bruge 2 vejs kommunikation mellem vores services, undtagen i de tilfælde hvor autoritet er vigtigere end autonomi – mere om dette i en senere blog-indlæg.
Bemærk: Høj autonomi er ikke nødvendigvis løsningen i alle tilfælde. Der kan være tilfælde, hvor brugen af 2-vejs kommunikation er mere omkostningseffektivt set ud fra et udviklingsmæssigt synspunkt eller hvor manglen på autonomi er noget som organisationen kan leve med (f.eks læsninger på tværs af mange tjenester).
I en given gammel monolit har vi f.eks. have samlet al funktionalitet og data relateret til et Detailhandels (Retail) domæne. Et sådan domæne vil omfatte funktionelle områder såsom Produkt-katalog, salg, lager, forsendelse og fakturering. Hvert af disse funktionelle områder kaldes også ofte for underdomæner (subdomains) eller forretningsområder (business capabilities):
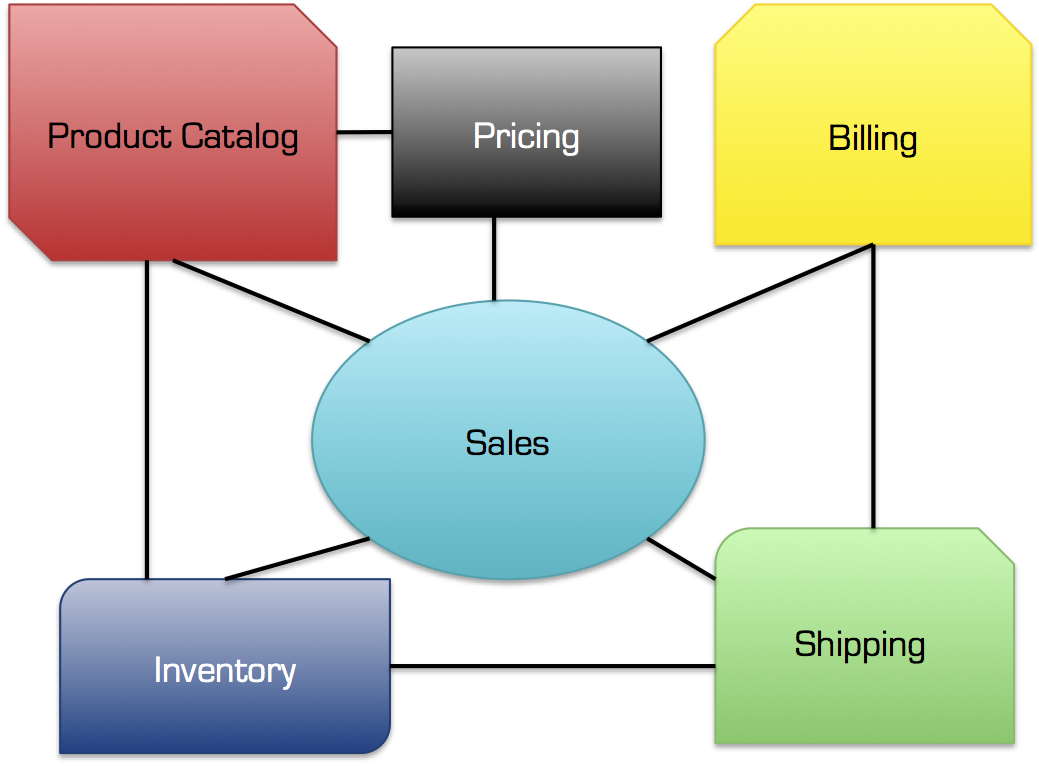
Funktionelle områder indenfor et detailhandels domæne
Detailhandel handler om at sælge produkter, så hver af disse funktionelle områder eller underdomæner, vil på en eller anden måde involvere domænet konceptet Produkt:
- Et produkt findes f.eks. i Produktkataloget underdomænet sammen med fx navn, beskrivelse, billeder osv.
- I Salgs underdomænet opretter vi ordrer på Produkter.
- I Lager underdomænet er vi interesseret i hvor mange emner af et givet produkt vi har på lager (QoH – Quantity on Hand) og fx hvor de er placeret.
Det er ikke sikker at vi benytter navnet produkt her. Nogen steder afhænger navnet af produktets lager tilstand, f.eks. en lagervare, en bestilt vare, osv. - I Pris underdomænet er vi interesseret i prisstrategierne for vores produkter. Dette kan også omfatte kunde-rabatter afhængigt af kundens status (som måske er gemt i en CRM monolit / service).
- I Forsendelses underdomænet vi er interesseret i størrelse og vægt af Produkterne plus hvor de skal sendes til, osv.
Hvis vi tænker over det, relateret alle underdomæner sig til og interesseret i produkter på den er anden måde. Underdomæner kan bruge det samme koncept navn, eller de kan bruge et andet navn end Produkt. Det samme gør sig gældende for andre domæne koncepter som f.eks. kunder.
De forskellige underdomæner er interesserede i vidt forskellige information i relation til produkter: Lager er fx interesseret i Stock Keeping Unit (SKU), Quantity On Hand (QoH) og Lokations koden. For dem er navnet på eller billedet af produkterne reelt irrelevant. Hvis Lager underdomænet skulle have brug for navn eller billede, ville det udelukkende være i form af visuel støtte til lager arbejderne så de nemmere kan udføre deres arbejde. Forsendelses underdomænet er ligeglad med QoH, Lokations kode, osv. De vil være interesseret i størrelsen af produkter emballage, vægt og måske navnet, hvis de skulle til at udskrive forsendelses kvitteringen.
I Domain Driven Design (DDD) kaldes dette for forskellige Bounded Contexts.
I en monolit ville det være meget nemt at definere en Produkt tabel med mange attributter / relationer og derefter tillade de forskellige underdomæner at inserte/update og joine data, som de ønsker. Resultatet er at Produkt database modellen vil blive meget stor, og den vil have mange grunde til at ændre sig fordi vi krænker Single Responsibility Principle (SRP). Koblingen i denne model er høj og samhørigheden (cohesion) er lav.
Du kan ikke ændre produkt tabellen/modellen, da mange andre er afhængige af den. Hvis vi tager udgangspunkt i et forfejlet design og bagefter service enabler den har vi blot flyttet vores afhængigheder fra databasen til service kontrakter og vores services vil ikke være autonome/selvstændige.
Hvordan definerer vi service boundaries (grænser)
Vi har brug for en måde at designe vores service boundaries, så vores services ikke behøver at tale med hinanden ved hjælp af 2-vejs kommunikation for at hente data eller påberåbe sig funktionalitet fra andre services.
Vi kan f.eks. starte med at bygge vores services omkring funktionelle områder eller forretningsområder (business capabilities), og bruge det som vores afgrænsning. Det betyder, at vores service vil være selvejende mht. data og funktionalitet.
Andre tjenester må ikke eje de samme data eller funktionalitet som vores service!
Der kan kun være én ejer af data. Med denne garanti på plads, kan vi stole på at vores service til at være den eneste kilde til sandheden med hensyn til alle dets data.
Ved at gøre dette sikrer vi, at vores service kun skal reagere på ændringer, hvis de forretningsmæssige funktioner, som den er ansvarlig for ændrer sig.
Dette er også kendt som Single Responsibility Principle (SRP) for services. Du kan læse en god diskussion om dette her og her.
Bemærk: Eksemplet nedenfor er tænkt som det første skridt i at bygge mere løst koblede services. Definition af service-boundaries er ikke let, så i de næste par blogindlæg vil jeg grave dybere i, hvordan vi kan definere bedre tilpasset service-grænser end hvad vi får fra rudimentær tilgang beskrevet her. Fx antager jeg at mange vil hævde, at produkt-kataloget er ikke den bedst definerede service, men da mange organisationer allerede har et produkt katalog medtager den her.
Lad os starte med Produkt-katalog servicen. Vi vil gøre denne service til vores eneste kilde for Produkt aggregat informationer så som: navn, id (husk et aggregat behov for et unikt id), billeder, beskrivelse osv.
Salgs servicen er ansvarlig for at opbygge Ordrer (med Ordrelinier) for Produkter som kunden ønsker at købe (køb kan f.eks. ske gennem webshoppen).
I Salgs servicen vores interesse i Produkter begrænset til prisen, kvantiteten og id’en på det Produkt hver Ordrelinie vedrører. Vi behøver ikke navnet på produkterne, for at opbygge en ordre i Salgs Servicen (vi har brug for navnet i webshoppen, men det er en read usecase og her fokuserer vi på skrive usecasen der opbygger en Ordre i Salgs servicen).
Med udgangspunkt i denne afgrænsning vil vores simplificerede service modeller kunne se således ud:
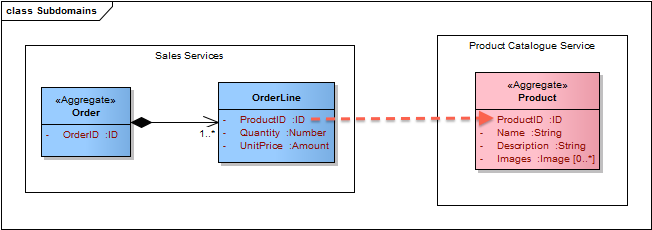
Simplificerede service modeller
De to service modeller ovenfor repræsenterer to meget rene datamodeller, der hver især har høj sammenhørighed og lav kobling. Den eneste kobling mellem de to er, at OrdreLinier refererer Produkter ved ID (husk reglen fra del 2 der siger at aggregates referencer hinanden ved id).
Webshoppen (der er klient af mange services) er ansvarlig for visning af produkter til salg samt den pris kunden skal betale for hvert produkt. Når brugeren er færdig med at fylde sin indkøbskurv, vil WebShoppen sende en kommando besked til Salgs servicen. Denne besked vil indeholde kvantitetet, enhedspris og produkt-id’er for alle de produkter kunden ønsker at købe. I en senere blog-indlæg vil vi se på, hvordan vi kan drage fordel af sammensatte brugergrænseflader (Composite UI’s) for at sikre en endnu lavere grad af kobling i webshoppen, men indtil da kan vi antage at WebShop kalder hver service med 2 vejs kommunikation (optimalt in process afhængigt af service deployment model).
Så længe Salgs service bliver forsynet med kvantitet, enhedspris og produkt-id, kan den oprette en Ordre og tilføje OrderLines uden at skulle tale med Produktkatalog service.
Men hvad sker der, når Salgs servicen ønsker at sende kunden en ordre bekræftelse?
Når brugeren modtager sin Ordrebekræftelse, fx via e-mail, han er interesseret i at se mere end priser, kvantitet og ID’er. Han ønsker at se navnet på og måske et billede af det produkt, han har bestilt, så han kan være sikker på at han får hvad han bestilte.
Så hvordan skal Salgs Servicen få fat i produktets navn, mv. fra Produktkataloget mens den danner Ordrebekræftelses email’en?
Lad os se på nogle af de muligheder Salgs Servicen har til rådighed:
- Den mest almindelige metode: Salgs servicen kan anvende 2 vejs kommunikation til at kalde Produktkatalog service for hver OrderLine i Ordren (enten som et kald for hver OrdreLine eller som et batch kald, der indsamler oplysninger for alle Produkter indeholdt i Ordren på een gang)
- Det betyder, at Salgs servicen nu har en stærkere kontraktlige og tidsmæssig/temporal kobling til produktkataloget servicen. Salgs servicen ved nu detaljeret hvilke operationer og data Produktkatalog servicen tilbyder/indeholder.
- Dette betyder, at når der sker ændringer i Produktkatalog tjenesten der ikke er bagudkompatible bliver Salgs servicen også nødt til at ændre sig. Alternativt skal produktkatalog servicen til at versionere sine kontrakter.
- Dette problem kan delvis løses hvis produktkataloget servicen tilbyder forbruger drevene kontrakter (Consumer driven contracts), hvor der er service klienten, fx Salgs servicen, der afgør hvordan dens individuelle kontrakt med Produktkatalog servicen bør se ud.
- Hvis produktkataloget servicen er nede, kan Salgs servicen, på grund af den tidsmæssige kobling, ikke oprette ordrebekræftelser. Dette vil i dette tilfælde formentligt ikke være et stort problem, da Ordrebekræftelser ikke er tidskritiske eller direkte eksponeret overfor kunderne i webshoppen.
- HVIS Salgs servicen også er ansvarlig for hele produkt renderingen i webshoppen (da den kunne eje webshoppen), vil den tidsmæssige/runtime kobling mellem Salgs servicen og Produktkatalog Service være for hård. Blot fordi produktkataloget (som fx kan være i et ERP system) er nede / utilgængelig må det ikke betyde, at vi ikke kan oprette og acceptere nye ordrer i Salg Service!
- Produktkataloget servicens UI er en del af af i Ordrebekræftelses genererings processen (UI mashup).
- Dette er en mere subtil og mildere form for kobling, da Salgs servicen ikke behøver at kende data i eller kontrakt for Produktkatalog servicen (bortset fra en meget lille delt rendering kontekst der er defineret af UI’en)
- Service mashup indebærer stadig tidsmæssig kobling mellem vores services
- Jeg vil komme tilbage til Composite UI / service mashup i et senere blogindlæg
- Det sidste eksempel ville være, at Salg Service indeholder en cache / kopi af Produktkatalog servicens data. Dette kan opnåes, uden tidsmæssig kobling til Produktkatalog Service, ved at bruge Data duplikering med Events.
Data duplikering med Events (hændelser)
Når produkter bliver tilføjet, ændret eller fjernet fra produktkataloget kan vi underrette andre services om denne kendsgerning ved hjælp forretnings events.
I dette tilfælde er Produktkatalog servicen så enkel, fra et forretningsmæssigt synspunkt, at de forretningsmæssige events minder om Opret / Opdater / Slet (også kendt som Create/Update/Delete – CUD events): ProductAdded, ProductUpdated og ProductDeleted.
Bemærk, at alle events er navngivet i datid, hvilket er et vigtig!
Hvis vi lader Salgs servicen lytte/abonnere på disse events over en Besked kanal (Message Channel), f.eks i henhold til Publish Subscribe mønsteret, bliver det muligt for Salgs servicen at opbygge sin egen interne præsentation af produkter med præcist de data den er interesseret i:

Data duplikering over events
Dette vil resultere i følgende service datamodeller:
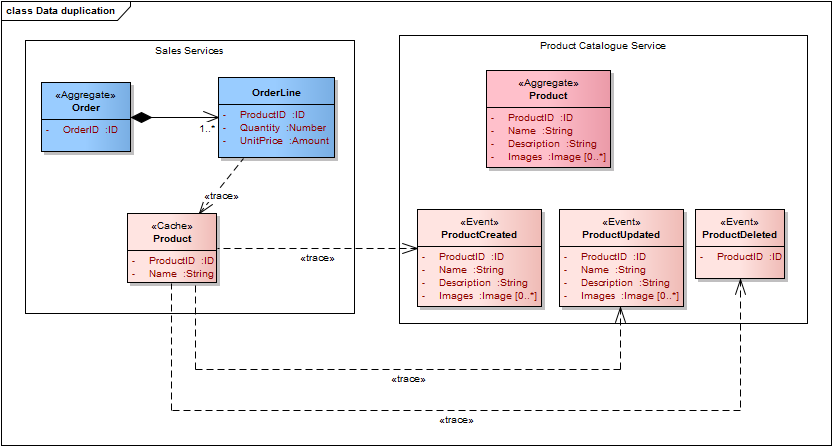
Service modeller med events og data duplikering
På grund af data duplikering med events har vi fået følgende fordele:
- Der er stadig et klart data ejerskab. Produktkataloget er ejeren af produkt stamdata og den vil underrette afhængige services, når data ændres.
- Denne form for data caching teknik er bedre end de fleste traditionelle caching mekanismer, hvor man typisk mangler enhver form for event eller tilkendegivelse fra ejeren af dataene, om hvornår de cachede data er forældede/ugyldige. Med events, du får besked så snart data ændres
- Den kontraktmæssige kobling er lavere. Du er kun bundet til Event kontrakter og de indeholder kun data. Event kontrakter er derfor meget enklere end klassiske Service kontrakter (fx WSDL) der både indeholder data og funktioner. Erfaringen viser, at event kontrakter har tendens til at være mere stabile.
- Graden af koblingen mellem produktkataloget servicen og salgs servicen er langt lavere.
- Salgs servicen behøver kun at kende event kontrakterne og adressen på event kanalen.
- Produktkatalog servicen har ikke nogen kobling til Salgs servicen. Produktkatalog servicen ved ikke hvad Salgs servicen har til hensigt at gøre med de events den modtager (indkapsling af logik).
- Vi har brudt den tidsmæssige/temporal kobling samt den tekniske kobling på bekostning af at være eventuel konsekvent.
- Dette ligger sig op af anbefalingerne og læringen i Pat Hellands “Life Beyond Distributed Transactions – An Apostate’s Opinion” (PDF-format). I artikelen konkluderer han, at man kun kan være konsistent inden for en enkelt Aggregate instans (dvs. inden for een transaktion og inden for een servicen), mens du nødt til at være eventuel konsistent mellem aggregate instanser (dvs. mellem tjenester samt mellem individuelle transkationer indenfor een service), fordi vi har ingen mulighed for at sikre sammenhængen mellem dem, medmindre vi er klar til at betale en meget høj pris ved at bruge distribuerede transaktioner.
- I dette tilfælde betyder eventuel konsistens, at hvis event besked kanalen er utilgængelig eller ude af stand til at levere beskeder til Salgs servicen, så vil vi skrive gamle produkt navne i Ordrebekræftelsen. Så snart besked kanalen er tilbage op, vil Salgs servicen indhente produktkataloget servicen. Eventuel konsistens er faktisk normen, når du bruger caching, uanset om du bruger events eller ej.
- Vi kan gøre eventuel konsistens problemet mindre ved at forankre events til tid. Dette kan gøres ved hjælp af navnet på og dataene i eventen. Dataene kan oplyse modtageren om hvor langt ud i fremtiden værdierne er gyldige og derfor cache-bare (produkt priserne ændrer sig måske en gang om dagen mens produktnavne sjældent ændrer sig, osv.)
Skeptikerne vil måske kigge på data duplikering med events og sige, at det ligner en masse arbejde for noget, der nemt kunne opnås ved eksisterende database teknologier. Hvis det er alt vi bruger events til, tager de ikke helt fejl.
Data duplikering med events er et velkendt, teknologineutralt, mønster for langsomt at skille monolitter op i selvstændige services, men det er ikke den endelige løsning for event baseret integration.
Vi kan gå et skridt videre og høste flere fordele. Vi kan bruge events til at drive forretningsprocesser.
Brug af forretnings events til at drive forretningsprocesser på tværs af services
Hvis vi ophøjer events fra simple Create/Update/Delete (CUD) hændelser til at være reelle forretningsmæssige events, der afspejler tilstands ændringer (eller fakta) i vores aagregates, kan vi bruge disse events til at drive forretningsprocesser uden at skulle ty til 2 vejs kommunikation for at koordinere vores forretningsprocesser (altså vi kan undgå orkestrerings problematikken langt hen ad vejen).
Lad os se på, hvordan vi kan drive Order opfyldelses processen ved hjælp af events. Når kunden trykker på Accepter Ordre knappen i webshoppen resulterer det i at en en AcceptOrder kommando besked bliver sendt til Salgs servicen:
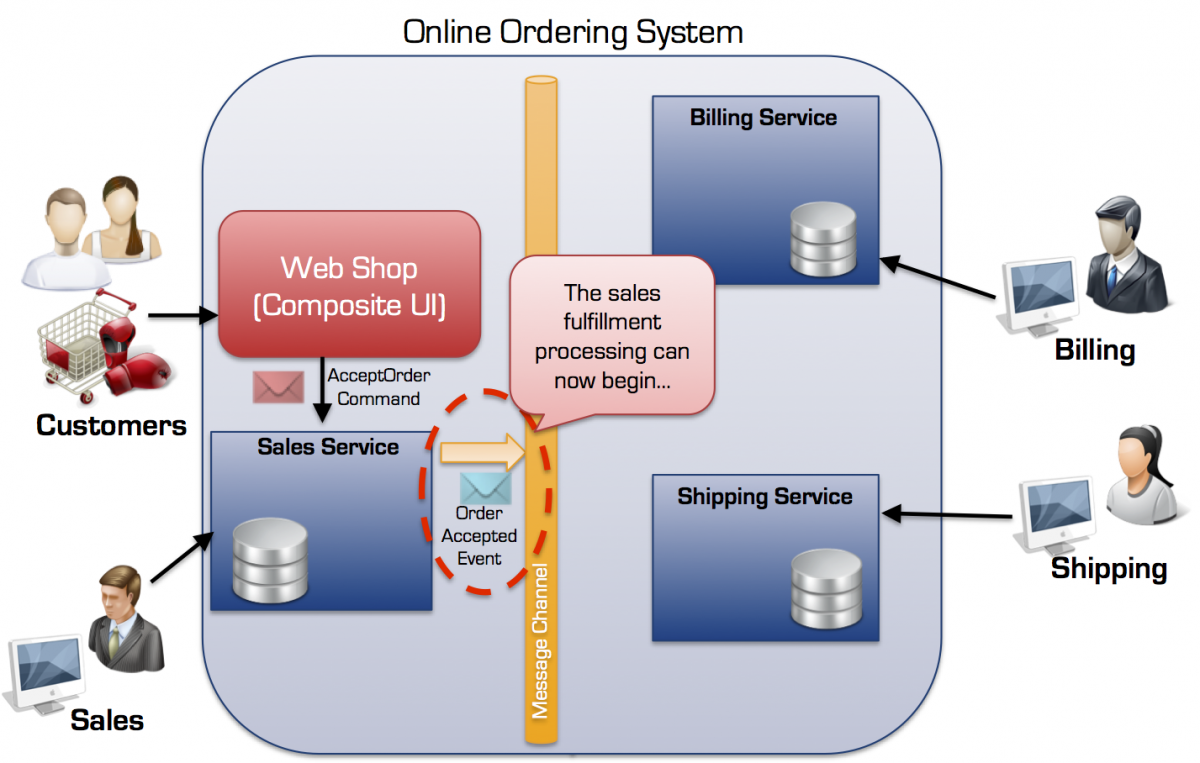
OrderAccepted eventen trigger Ordre opfyldelses processen
AcceptOrder kommandoen resulterer i en tilstands ændring i Ordren, der som følge heraf transiterer til tilstanden Accepteret.
Denne tilstands ændring (eller faktum) bliver kommunikeret til alle interesserede services som en OrderAccepted event – på den måde angiver vi, via OrderAccepted event’en, at Ordren er blevet accepteret, hvilket er en irreversibel ændring (den kan kompenseres, men den kan ikke rulles tilbage).
Salgs servicen ved ikke hvem der er interesseret i event’en, men på virksomhedsniveau har vi indøvet vores ordre opfyldelses proces og aftalt hvilke services bør reagere på OrderAccepted eventen.
Dette kaldes også for reaktiv programmering eller Event Driven Architecture (EDA) og det er meget forskelligt fra den klassiske BPEL inspirerede Orkestrerings tilgang, hvor der er en central dirigent der koordinerer og instruerer services om hvad de skal gøre.
Med EDA bestemmer vores services selv hvad de vil gøre når en event indtræffer. I de scenarier, hvor vi har behov for at koordinere flere services, fx for at sikre, at vi ikke udfører leverances inden kunden er blevet faktureret og alle produkter er på lager (eller hvad kriterierne for leveringen nu er) vil vi indføre en ny Aggregate der vil være ansvarlig for ordre opfyldelses processen. Hvorvidt denne proces aggregat hører til i Shipping servicen, eller om den er en selvstændig service (som vist nedenfor), er ikke så vigtigt lige nu. Det vigtige er, at vi har identificeret en central forretnings funktionalitet (business capability) som vi eksplicit tildeler ansvar.
En sådan proces aggregat kan implementeres / understøttes af en Process Manager eller en Saga (som det hedder i Rebus og NServiceBus). Processen kan vælge at instruere andre tjenester om hvad man skal gøre (dvs. delvis orkestrering) hvis det er nødvendigt, men generelt kan meget løses ved hjælp af events alene (vi vil i et senere blogindlæg komme ind på hvornår at favorisere andre meddelelsestyper såsom Kommando beskeder eller dokumenter istedet for event beskeder).
I nedenstående eksempel afventer Order opfyldelses servicen på to events, OrderAccepted og CustomerBilled, før det publiserer OrderReadyForShipping eventen (i dette tilfælde kunne vi også har sendt en ShipOrder kommando til Leverings servicen, men lad os holde fast i events for nu).
Koordinering af de to events kræver at de begge indeholder tilstrækkelige oplysninger til at indikere at de er relateret til den samme Ordre opfyldelses proces instans. Dette kunne eksempelvis være i form af en OrderID eller anden form for Korrelations id.
Denne form for samordning mellem services ved hjælp af events er også kendt som koreografi.
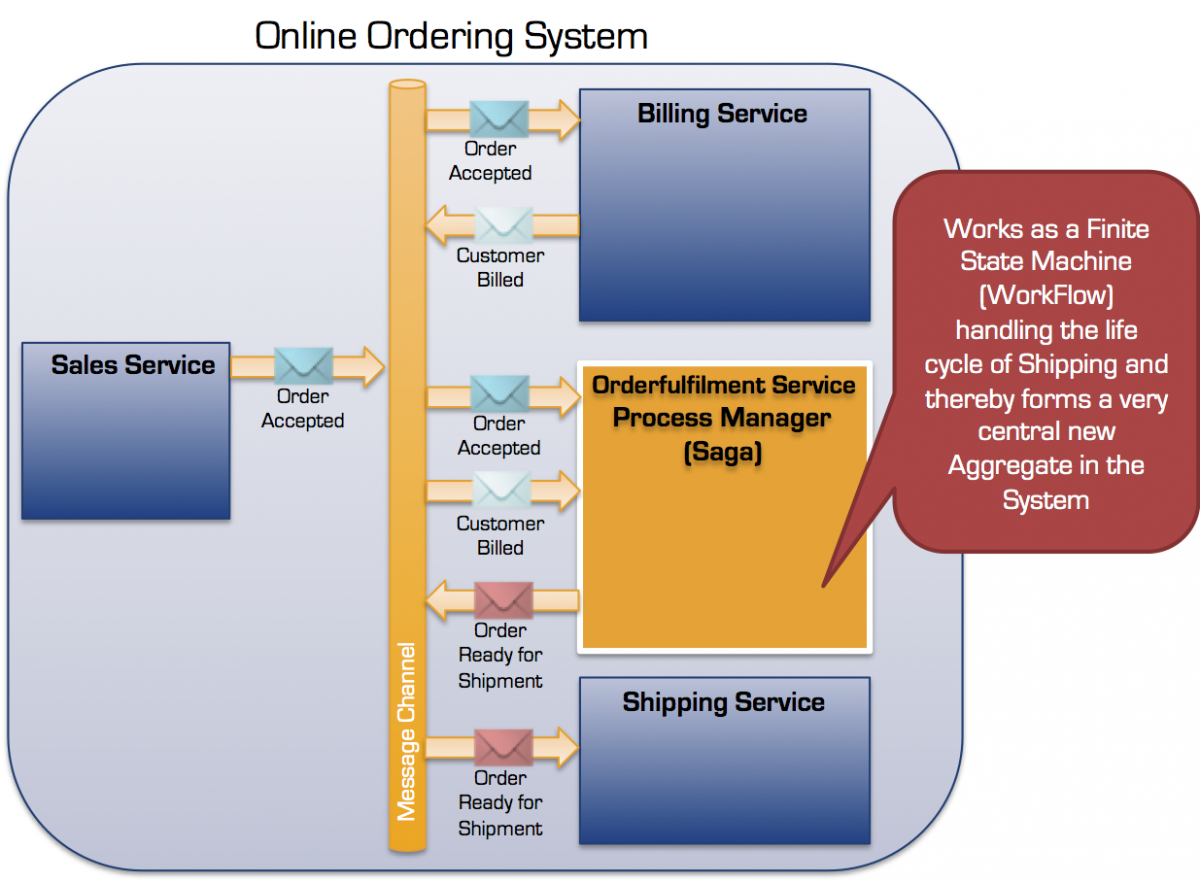
Den koreograferede Ordre opfyldelses process
Der er meget mere at sige om Event Driven Architecture (EDA), service boundary definition, men dette blog-indlæg er allerede langt nok, så det bliver nødt til at vente til næste gang.
English version: Microservices: It’s not (only) the size that matters, it’s (also) how you use them – part 4
[…] Del 1 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem Del 3 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem Del 4 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du… […]
[…] Del 1 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem Del 2 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem Del 4 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du… […]
[…] Del 2 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem Del 3 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem Del 4 – Microservices: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du… […]