Den kode du skrev i går er legacy i dag. En stående joke i branchen som jeg bittert må erkende, taler visse sandheder om den kode jeg skrev i går. Det er softwareudviklerens fordel og ulempe at alting flytter sig; metoder, evner, og krav.
Det er sjovt at kigge tilbage på den udvikling man har været igennem som softwareudvikler siden man første gang stødte på termer som objekt-orienteret-udvikling, lag, klasser og sekvensdiagrammer. Hvor meget af lærdommen har fulgt med hele vejen og danner grundlag for arbejdet i dag. Hvor meget er blevet forkastet?
Lagdeling var en af de fundamentale begreber som vi er blevet flasket op med under hele studieforløbet. Der var mange andre facetter af softwareudvikling som vi aldrig nåede at forstå fuldt ud men lagdeling lå lige til højrebenet og det er også en af de ting der har fulgt mig langt ind i karrieren.
En lagdelt arkitektur holder også et godt stykke af vejen; med lag organiserer man sin kode så den er delt ind efter funktion:
- Grafisk grænseflade
- Servicelag
- Forretningslogik
- Service-kommunikation
- Database-kommunikation
Resultatet er, at man fx. i isolation kan skabe nye forretningsregler uden at tænke på, hvordan de skal vises til brugeren eller gemmes i databasen. Og det er fundamentalt; enhver arkitektur ender med at være så kompleks at vi mentalt ikke kan overskue den, så derfor er vi nød til at gemme dele af den af vejen.
Med tekniske briller er det en behagelig måde at arbejde på – vi kan sætte os ned og arbejde på ét lag og lave en rigtig lækker indpakning der performer godt, har det helt rigtige interface og skal vi en dag skifte database eller grænseflade skal vi kun ind og rode ét sted.
Mange bøger, frameworks, biblioteker og skoler lægger op til at det er måden at strukturere på. Men hvordan harmonerer det med den måde at vi arbejder på?
Problemet
De fleste af os arbejder på at løse forretningsproblemer. Mange gange kan en opgave koges ned til at skulle tilføje et eller flere felter, om det så er visning af de data vi har på en ny måde, tillade noget nyt brugerinput eller indføre en ny forretningsregel.
Resultatet er, at vi skal ind og rette ét eller flere lag. Den helt simple opgave med et nyt felt i grænsefladen kræver en ændring i samtlige lag for at kunne fungere. Og her ryger den mentale model fra før, det kan godt være at arkitekturen er nemmere at overskue, fordi dele er gemt af vejen, men vi er tvunget til at kigge på alle disse dele for at kunne løse opgaven.
Ikke nok med det, vi har intet overblik over hvilke sideeffekter vores ændring må få – da vi ændrer i alle lag er vi faktisk nød til at teste det hele igen.
Features
Med features eller feature drevet udvikling deler vi vores arkitektur op i hvilke features vi skal kunne tilbyde. En feature kan være alt lige fra et forretningsproblem til et rent teknisk problem.
Er man i tvivl, om hvor man skal lægge cuttet, er et godt sted at starte med det der i Domain Driven Design (DDD) kaldes for rodaggregater.
Rodaggregater er klasser, hvis objekter ejer andre objekter. Et typisk eksempel er en ordre der ejer dens ordrelinjer, så her er ordren et rodaggregat – hvis en ordre slettes, så gør ordrelinjerne typisk også. Men en bruger hører ikke med til dette rodaggregat, da den har en anden livscyklus end ordre.
Dermed ikke sagt, at vi ikke må dele det yderligere op ideelt lever hver nye feature som forretningen beder om i sit eget lille område. Og ideelt set kræver hver ændring, at vi kun skal ændre i én feature.
Desværre betyder det ikke, at vi kun skal teste denne ændrede feature, for features er afhængige af andre features. Man kan godt gøre disse bindinger lettere ved at benytte sig af events, service busser osv. men jeg mener nu at nogle få afhængigheder er ok, ellers bliver den enkelte feature for stor, da den skal kunne alt.
Konsekvensen er, at vi reelt får en graf af afhængigheder, som vi kan mappe ud, og som kan fortælle os, hvad vi skal teste:
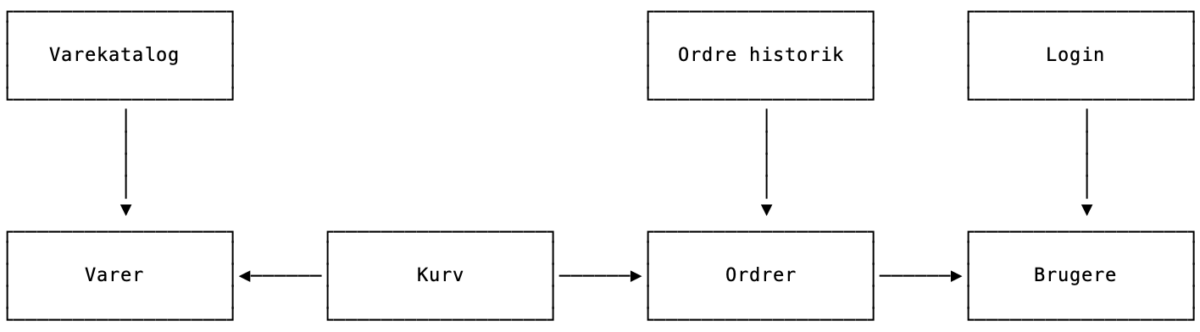
Afhængig af behov kan en feature stadig indeholde lag. Er man tilhænger af et separat database-lag kan det sagtens leve som små lag i hver feature. Måske endda hver med en afhængighed til en database-feature, så man har et sted at placere den infrastruktur, der går på tværs af alle features.
I visse projekter kan der være behov for at udstille både et API og en grafisk snitflade – og dermed kan det være nødvendigt lade samme feature leve i flere lag. Hermed adopterer vi problemet med at skulle rette flere steder i forbindelse med ændringer, men vi bevarer en vis isolation. Ydermere kan der sagtens være features, der kun lever ét af stederne, fx. førnævnte database-feature som kun lever i vores kerne-lag og ikke i grænsefladen. Ligeledes kan det være at vores ordre-historik-feature kun lever i grænsefladen.
Laver vi testdrevet udvikling, lever vore tests som regel også separat, da de ikke skal med ud i produktion, når vi deployer. En typisk måde at strukturere testprojekter på er, at lade dem afspejle det testede projekts struktur – så man får et en-til-en forhold mellem produktionskode og tests.
Det giver en folderstruktur der ser sådan her ud:
- Grænseflade
- Features
- Ordre historik
- Varekatalog
- Features
- Grænseflade-tests
- Features
- Ordre historik
- Varekatalog
- Features
- Kerne
- Features
- Varekatalog
- Features
- Kerne-tests
- Features
- Varekatalog
- Features
Man kunne her godt undvære folderen features, men de fleste frameworks og biblioteker har for vane at skabe anden støj i rodfolderen, så vil man have en ren liste af features, er det at foretrække en separat folder.
Der er mange andre fordele ved opdeling ved features, eksempelvis Feature toggles hvor man tillader features at leve i produktion, men kan slå dem til og fra. Og det at vi har alt koden relateret til en feature liggende samlet åbner op for flere måder at eksponere versionering. Har vi behov for bagudkompabilitet kan vi fx. vælge at fryse en feature og lave alle nye tiltag i en kopi.
Sidst er der alle de fordele isolation af kode giver. Det gør, at vi kan skabe kode, mens vi stræber efter principperne omkring god kode; single responsibility, høj samhørighed, lav kobling osv.
Det kan være, at det allerede er sådan, du arbejder i dag – og at du ikke kan genkende den problematik, som jeg nævner i starten. Jeg har dog mødt flere teams og arbejdet sammen med mange, der blot kigger underligt på mig, når jeg begynder at snakke om disse principper. (der ligger mig så nært).
På GOTO i København skal Casey Rosenthal holde et indlæg om den kompleksitet, der opstår, når vi skaber features. Hvordan vi kan lære at genkende den og forholde os til den. Noget som måske kan gå hånd i hånd med isolerede features.
Forside-billede fra Applying UML and Patterns af Craig Larman
Personligt har jeg altid løst problemet med kun at have ét varchar felt i alle mine tabeller. Så gemmer jeg alle properties i et XML-lignende format. Jeg har i parantes bemærket opfundet mit eget smarte markupsprog som jeg er ved at patentere. Så kan man tilføje felter i vildskab uden at rette i alle lag. Når bare man loader hele modellen ind ved startup så spiller det.