Når der er nogen som siger at de har løst alle de store udfordringer i et komplekst problemområde, så bliver jeg normalt lidt skeptisk, men alligevel nysgerrig (om ikke andet bare for at finde huller i det). Så da jeg læste om en ny machine learning open source platform, begyndte jeg straks at downloade.
Den bliver præsenteret som skruetrækkeren der passer på alle bigdata-skruer, og den skulle dreje meget hurtigt. Introvideoen nævner 1000 gange hurtigere end R, så må man jo prøve.
Vidunderet er navngivet H2O, og skulle kunne håndtere store datamængder, problemer med langsomme algoritmer, og gøre det at lave analytics for dit firma…. en simple sag. Og så laver den også cappuccino med ekstra cremefuld skum, eller? Nej. Det er en data-engine, som betyder at det er god til at tage store mængder af data og lave beregninger med det. Map Reduce er det gamle sort i Big data-moden, men mange er begyndt at kigge på andre mønstre for at processering af data[1], og her skulle H2O være stedet og gå hen, da det både skulle være hurtigt, men også virke sammen med Hadoop. Forvirret? Det er jeg.
For at teste hvor nemt det er, besluttede jeg at prøve at udnytte samme algoritme som beskrevet i en tidligere indlæg ved navnet K-means og se om jeg kan slå min nuværende position på den Kaggle-konkurrence som jeg skrev om i samme indlæg.
H2O er nem at få op at køre, blot download en jar fil, og kør den, og vupti har du et web interface som kan indlæse dataset og lave segmentering og regression.
Det virker som om at der er stadig nogle børnesygdomme og det er ikke altid klart, hvad det er man skal fylde i de forskellige felter, hvad betyder f.eks. “type Iced”? , men jeg er sikker på at det bare kræver lidt ekstra tid, og så snart man har kravlet lidt længere op af indlærings kurven, giver det hele mening.
Den time jeg havde sat af til at prøve at få H2O til at løse min kaggle opgave var ikke nok. Det lykkes mig at indlæse data, 73Mb, det tog cirka 10 sek, og en stikprøveudtagelse siger at data ser okay ud.
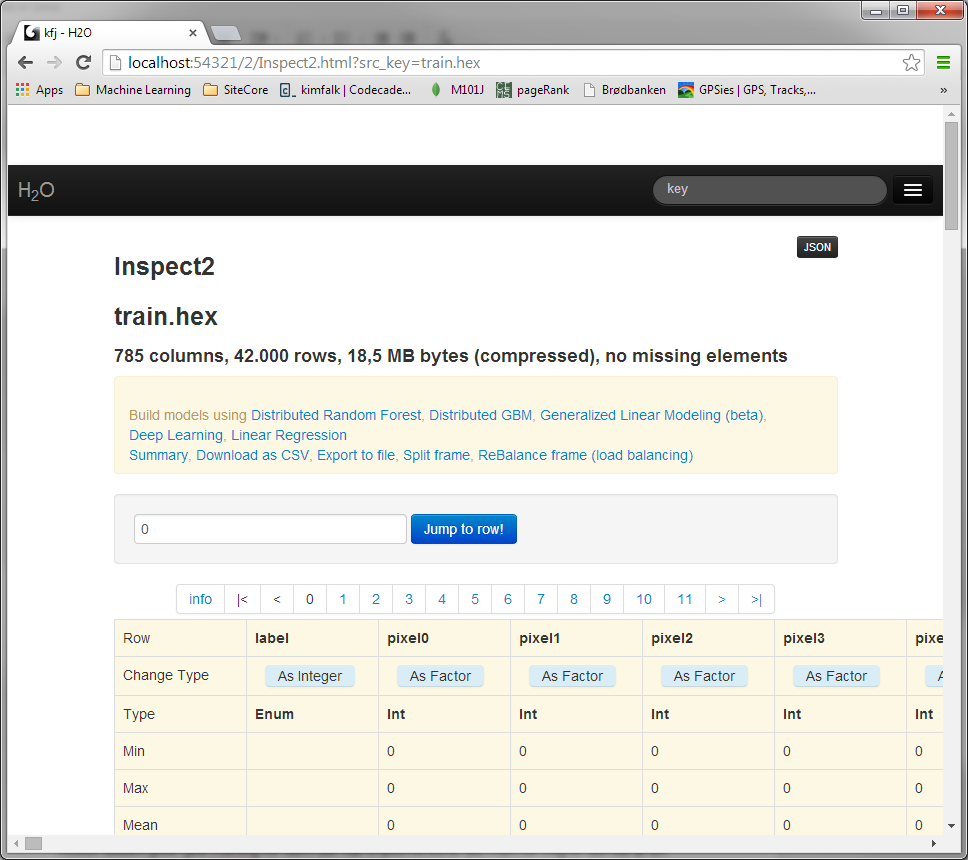
det samme med testdata. Man da jeg nu gerne vil lave en prediction på mine testdata, går det galt: Hver gang jeg prøver får jeg fejlen:
Error: water.fvec.Frame cannot be cast to water.OldModel
hvilket sikkert giver god mening for dem der har implementeret det men for mig er det lidt af en showstopper. For at se hvor hurtigt den faktisk er, prøvede jeg at lave en klassificering af testsættet, det gik ret hurtigt, men det fandt ikke noget der ligner de samme clusters som var givet, men om det er data eller algoritmen kan jeg ikke svare på, men under alle omstændigheder så der er måske også lidt mere der skal undersøges.
Alt i alt virker det som en spændende platform, som jeg har tænkt mig at lege lidt mere med. I dokumentationen står der noget om et RESTfull api også, hvilket jo kunne være sjovt at snakke med gennem noget C# kode. Men som med de fleste ting, kræver det lidt tid at sætte sig ind i hvordan det fungerer. Jeg er ikke helt overbevist om at det er så simpelt som introvideoen lover.
Men kan man overhovedet forvente at det er muligt at lave et simpelt værktøj til noget så komplekst som machine learning algoritmer? Jeg ville være nervøs for, at nogle af de ting som udelades i et simpelt interface er de parametre som gør forskellen på en god analyse eller ej.
Også nysgerrig? Så kan det være vi ses på GOTO enten København eller Århus og høre chefen bag firmaet OxData som står bag H2O, præsentere vidunderet i en talk. Præsentationen hedder “Fast Analytics on Big Data” og gives fredag i København d. 26 september på GOTO konferencen. Her håber jeg på at han vil fortælle noget mere om de datastrukturer som bliver brugt internt, og om algoritme-implementeringer. Men er også meget nysgerrig for at høre om hvilke løsninger der er blevet lavet omkring platformen.
[…] ikke så længe siden skrev jeg om H2O (link) , der er et nyt open source machine learning platform, som skulle gøre machine learning […]