Læste I dr.dk’s artikel om panama-papirene? Deri kan man læse at panamapapirene angiveligt indeholder informationer om 5-600 danskeres skattely-aktiviteter.
De papirer der omtales er en del af de 11,5 millioner dokumenter, som er blevet lækket fra virksomheden Mossack Fonseca i Panama. 11,5 millioner dokumenter er det det samme som 2000 kopier af hele Game of Thrones bog-serien (altså 14000 bøger, hvis altså man antager at 1 dokument indeholder ligeså meget tekst som en side i en GoT bog). Hvordan finder man noget som helst i dem?
Det kan man lære mere om hvis man tager til GOTO og hører Michael Hunger’s præsentation omkring hvordan man rent praktisk løste problemet om at skulle hitte hoved og hale i så mange dokumenter. Ifølge ham så blev der brugt både Solr, som laver søge-indekser, samt Neo4J som er en graf-database.
Hr. Hunger arbejder for Neo4J så det kommer nok mest til at handle om Neo4J, men jeg glæder mig alligevel til en spændende fortælling om hvordan Big Data-løsninger kan hjælpe med at tvinge folk ud af skattely.
Det jeg glæder mig til at høre om er, hvordan de har parset dokumenterne ind i graf-databasen. Selvfølgelig er der forfattere af dokumenter, men hvordan mon de har forbundet mennesker og instanser i en graf?
11,5 millioner dokumenter er rigtig mange og det er svært at overskue over 2,6 Terabyte, men der er blevet gjort et forsøg, som der er blevet offentliggjort gennem websiden: https://offshoreleaks.icij.org/.
Hvis man søger på personer kan man se Neo4J’s grafstruktur skinne igennem, i og med at man får følgende grafer ud af det:
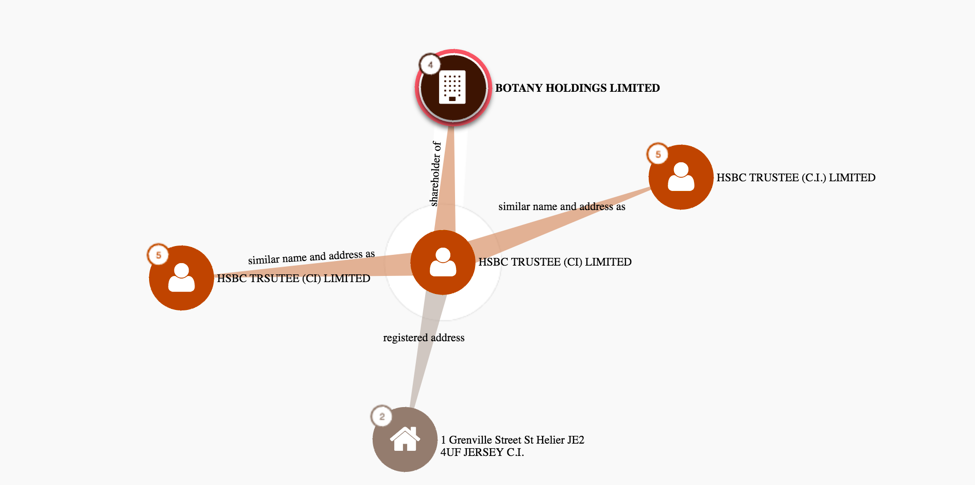
Stay tuned for more details after the presentation.